{kind=link}
어차피 여기서 중요한건 DQN이 어떤 동작과정을 통해 만들었는지이기 때문에 네트워크 동작 방식과 알고리즘을 중심적으로 알아보고, 간단하게 nature에 올린 글에 대해서 정리해보고자 한다!
배경지식
기존의 Q-learning은 CS231n 14. Deep Reinforcement Learning와 On policy VS Off policy + Q Learning 심화에서 나와있다싶이 target을 sample을 한 후 최적의 policy를 찾는 과정이었다면 DQN(Deep Q Network)는 DNN(Deep Neural Network)에 regression을 합친 것으로 볼 수 있다. 기존에는 incremental MC를 이용해 update 했다면, 이제는 에서 w라는 weight를 사용해서 여러 Q-function을 최대한 잘 표현하는 regression을 만든다. 이는 state가 매우 많아짐에 따라 똑같은 state를 사용하는 경우가 사실상 없어지고, 이에 따라 regression을 이용해 비슷한 경우에 비슷한 행동(action)을 하기 위해서 사용되게 되었다.
즉, gradient를 이용하여 w를 update하는 과정 로 이는 곧 새로운 sample이 들어오면 값(0~1)만큼의 영향으로 MC update가 됐던 것처럼, 여기서는 (learning rate)만큼의 영향으로 일부분 update되는 것이 DQN에 핵심이다 .(즉, update 방식은 유사하다)
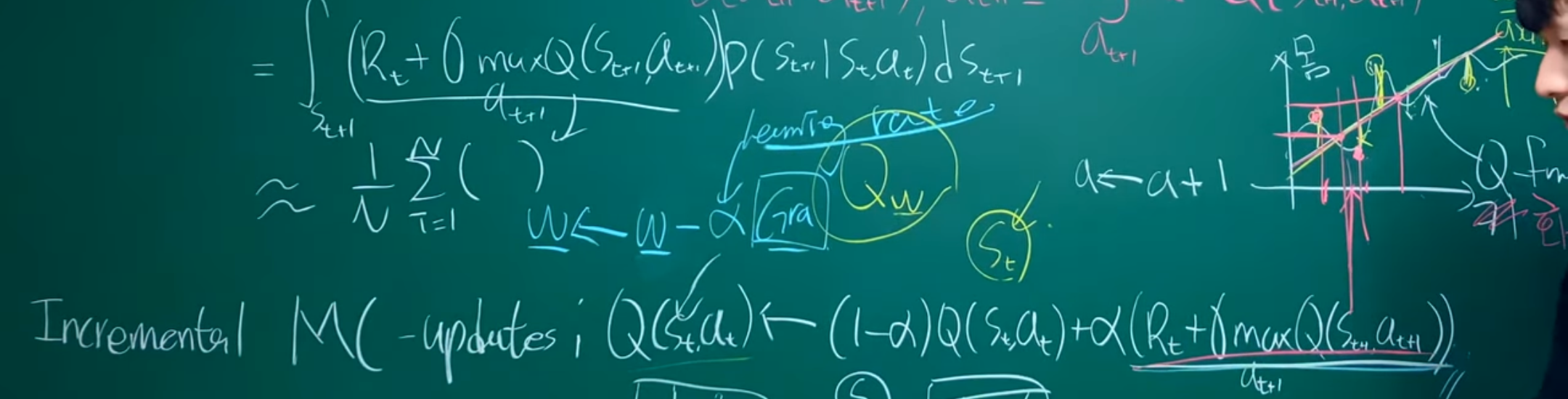
Methods
Preprocessing(전처리)
Atari 2600의 이미지를 바로 가져와 학습을 시키기에는 높은 연산과 저장 장치가 필요로 하기 때문에 전처리가 필요하다. 이에 따라 다음 2가지 방법을 통해 전처리를 진행했다
- 각각의 frame을 encode하기 위해 각 픽셀의 색깔 값마다 최대값을 구함. 이를 통해 하나의 frame에서 알 수 없는 값들을 이전의 frame과 비교하여 이해를 할 수 있게 만들어
의미있는 state가 될 수 있도록전처리를 진행 - Y channel(밝기)를 뽑을 때 ø 함수를 이용하여 84X84 크기로 rescale한다. 이때 ø 함수는 m개의 가장 최근 frame을 모아 Q-function의 입력값으로 들어가게 만든다
Model Architecture (모델 구조)
- [!] input을 state-action 쌍이 아닌 state로 넣은 뒤 output이 action 만큼 나오게 만들어 maxQ를 구하는 과정을 효율적이게 바꿈
neural network에서 Q를 parameterize하는 방식은 여러가지가 있다. 기존의 Q-value값을 평가하기 위해 state-action쌍이 neural network에 input이 되었는데, 이는 각 action마다 forward pass를 다르게 진행해야한다는 점에서 문제가 있었다. 이에 따라 현재 state만을 neural network의 input이 되게 만들어, output이 input state안에 각각의 action 값에 따라 Q-value값을 예측하도록 하였다. 이를 통해 단 한번의 forward pass로 가능한 모든 action들의 Q-value값을 계산할 수 있었다.
이 부분이 유튜브 강의에서 말한 특이한 부분으로 예를 들어 왼쪽,오른쪽으로 갈 수 있는 action이 있다면 각각의 action들이 input으로 들어가는 것이 아닌 state가 input으로 들어가고 후에 action들에 따라 Q-value값이 결정되는 구조이다. 이 부분을 자세히 설명하면 다음과 같다
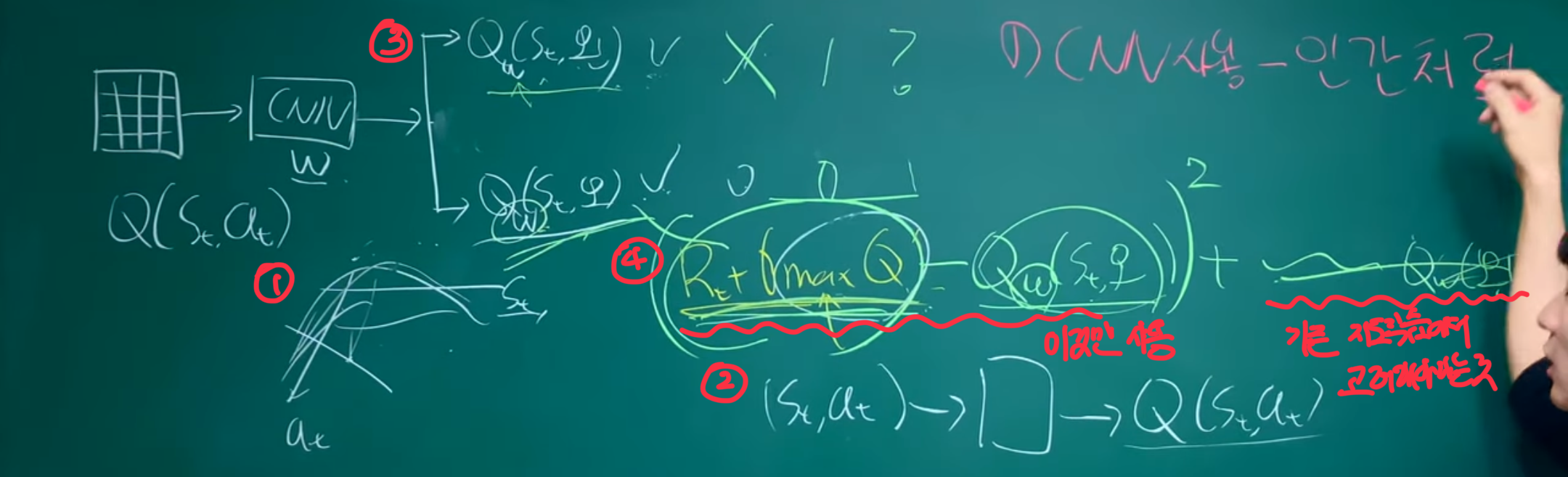
- 본래 Q값을 regression을 하기 위해서는 평면 위에 z축에 Q값이 존재하고, 이에 따라 3차원 공간상에서 regression이 진행되어야하는데 이 논문, 그리고 추후에 논문에서는 를 고려하지 않고 state 만을 고려한다는 것이다.
왜 이렇게 하는걸까? - 기존의 방식, 즉 state-action 쌍이 neural network에 input이 되면 각 action마다 Q값이 생성되게 될 것이다. 여기서 문제는 이 action 중에 reward가 최대인 policy를 찾아야하는데 그렇기 위해서는 n개의 action에 대해 모두 CNN을 돌리고 그 output을 비교해서 가장 최대의 값을 찾아야하기 때문에 비효율적인 것이다.
- 반면에 state만을 input으로 넣고 CNN을 돌린 후, n개의 action 만큼 output이 나오면 이 값을 가지고 최대인 Q값을 얻을 수 있기 때문에 효율적으로 계산이 가능하다.
- 또 하나의 특징은 loss를 구하는 방식에 있는데, 보통의 지도학습에서는 n개의 결과에 대해서 label을 통해 각각 loss를 구하지만, 여기서는 max인 특정 행동을 고르기 때문에 그 결과에 대해서만 loss를 구한다.
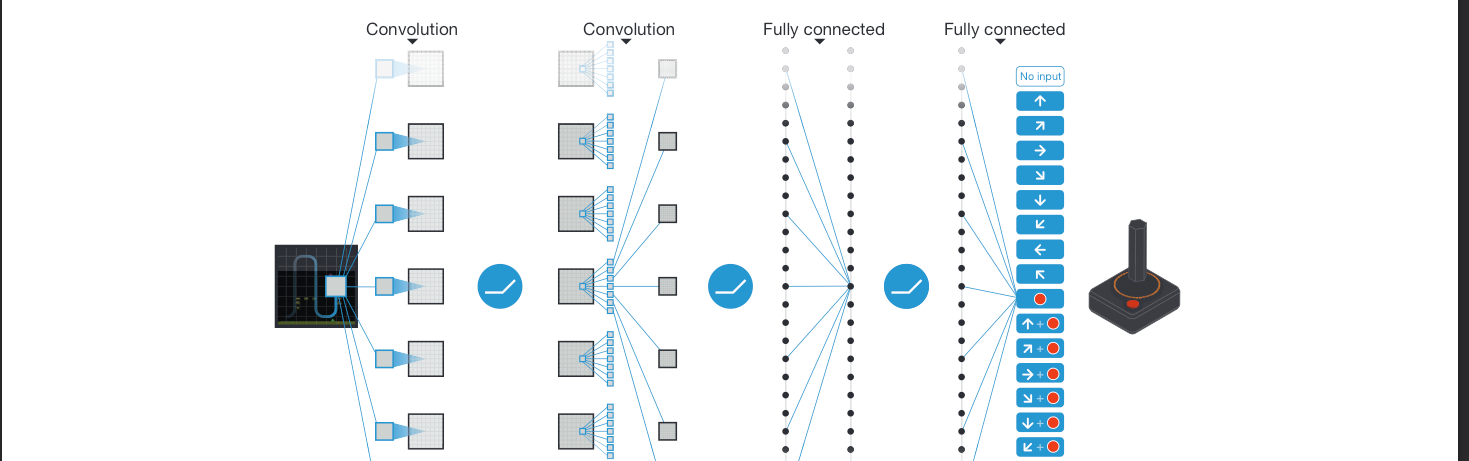 위에서 언급한 preprocessing(전처리)를 통해 기존의 image를 ø 함수를 이용하여 84X84X4(4개의 frame을 같이 보겠다!)로 만들어 hidden layer들을 통과한 후 fully-connected layer을 통과하여 각각의 action에 맞는 output을 도출했다. 이때 action은 게임에 따라 4~18개로 다양했다.
위에서 언급한 preprocessing(전처리)를 통해 기존의 image를 ø 함수를 이용하여 84X84X4(4개의 frame을 같이 보겠다!)로 만들어 hidden layer들을 통과한 후 fully-connected layer을 통과하여 각각의 action에 맞는 output을 도출했다. 이때 action은 게임에 따라 4~18개로 다양했다.
Training details
- [!] 다른 구조는 다 똑같고, 학습 중 reward 방식만 조금씩 다르게 학습하여 일반적으로 우수한 성능을 가져옴
-
frame-skipping사용 - informal search로 hyperparameter을 정함
이 모델이 효과적인 가장 큰 이유는 매우 일부분의 prior knowlege만을 통합하여(아래에 다시 등장) 똑같은 구조와 알고리즘, hyperparameter로 모든 게임에 적용하여 높은 성능을 낸 것이다. (결국 얼마나 좋은 모델인지는 일반화 및 적용가능성의 정도에 달려있는듯) 이때 유일하게 바꾼 각 게임마다 trainging때 바꾼 것이 reward 방식으로 이후에 scale이 다른 점수들을 clipping하여 positive reward를 1로, negative reward를 -1로 만들어 error의 정도를 줄여 여러 게임에 똑같은 learning rate를 사하기 쉽게 만들었다.
RMSprop 알고리즘과 사이즈 32의 minibatch를 사용했고 behaviour policy의 경우 -greedy를 사용하여 처음 백만개 frame에는 0.1~1.0의 값으로 experiment에 비중을 두었고 이후에는 0.1로 고정시켜 optimal policy를 찾게 만들었다.
위에서 간단히 언급했던 frame-skipping 역시 사용한다. agent가 모든 frame마다 action을 하는 것이 아니라 k개의 frame마다 action을 하는 것이다. 이는 결국 연속적인 frame에서 큰 차이가 없는 상황에서, 연산을 더 줄이고 더 많은 게임을 주어진 시간 내에 할 수 있기 때문으로 이 논문에서는 k=4인 것일 때를 사용한다.
hyperparameter과 optimization parameter의 경우는 grid search(높은 연산비용 요구) 대신에 informal search(경험을 통해 구하는 방식)을 이용한 후 그 결과를 모든 게임에 적용하는 방식을 사용했다 CS231n 6-2. Setting Up the Data and the Loss
위에서 언급했던 “매우 적은 부분의 prior knowledge만을 통합하여 모든 게임에 적용할 수 있는 모델을 만들었다”라고 말한 부분에서 prior knowledge에는 다음과 같은 것들이 있다.
- input data로 들어오는 visual image ⇒
ø function을 통해 변환 - 게임의 구체적인 점수
- action의 개수 (게임마다 다를거임)
- 목숨의 수
⭐️Evaluation procedure
- [!] baseline을 만들 때도 터무늬 없는 모델 대신에
실제 인간이 도달할 수 있는 최상의 결과를 모델링하는 것이 바람직한듯(결국 목표가 “사람”보다 뛰어난 성능을 만드는 것이기 때문!)
학습된 agent(trained agent)는 overfitting의 확률을 줄이기 위해, 매번 무작위한 initial condition에서 5분간 30번의 게임을 진행하여 평가를 진행했다. 이에 대항해 비교가 되는 baseline인 random agent-10Hz는 10Hz(6 frame)마다 action을 수행하게 설정하였다. (10Hz로 설정한 이유는 사람이 인식을 한 후 가장 빠르게 버튼을 누를 수 있는 시간이고 터무늬 없는 baseline을 만들지 않기 위함!) 또한 매 frame마다 action을 수행하는 random agent-60Hz baseline도 만들었지만 소수의 게임(5%)정도만이 성능이 향상되었고 실제 차이는크지 않았다. 결론적으로 상당한 차이로 DQN모델이 baseline 모델(인간)을 뛰어넘었다.
또한 같은 emulator engine에서 professional human tester에 대한 실험을 진행하였다. 이때 60hz 환경에서 audio를 들을 수 없게 하여 sensory input이 인간과 agent가 같게 만들었다 (최대한 비슷한 환경에서 실험을 진행하게 만듦) 이때 평균 reward는 2시간의 게임 연습 후, 최대 5분간 20 epiosode의 reward의 평균으로 정하였다.
Algorithm(알고리즘)
- agent는 emulator의 화면만 보게 되고 전체적인 상황을 확인할 수 없어 MDP 사용
- agent의 목표는 미래의 reward를 최대화하는 것이고, 이때 optimal action-value function을 사용하며 Bellman equation을 통해 update가 가능하게 만든다
- 정확히 업데이트 때는 function approximator을 이용하여 를 학습시키는 것을 목표로 하며 approximate target value를 설정하여 los를 구한다
- model-free이며 off-policy인 것이 특징
각 step마다 agent는 action을 선택하고, 이 action이 emulator로 넘어가 state와 게임 점수를 변화시키게 된다. 이때 agent는 emulator 내부를 알 수 없으며 대신에 emulator의 화면만 보게 된다. 이후 게임 점수에 따라 reward를 받게 되며 이때 게임 점수는 기존의 action들의 집합에 의해 결정되게 된다.
즉, agent는 현재 screen만을 관찰하기 때문에 전체적인 상황을 확인할 수 없으므로 action들과 관찰한 결과들의 연속(sequence)를 통해 학습이 진행되어야한다. 이에 따라 MDP(Markov Decision Process를 사용하게 됐다고 한다.
결국 agent의 목표는 emulator와 상호작용하여 미래의 reward를 최대화하는 action들을 뽑는 것이다. 이때 discount factor (0.99)를 이용하여 reward를 사용하고 으로 계산이 된다. (reward) 또한 어떤 policy이든지 간에 몇개의 sequence s 후에 a action을 취했을 때 기대할 수 있는 최대 return 값을 정의한 optimal action-value function(Q-function) 를 설정하였다. (optimal Q)
이때 optimal action-value function(Q-function)은 Bellman equation을 따르는데 간단하게 설명하면 next Q를 알면 현재 Q의 값을 알 수 있따는 것이다. 즉, 다음 step에서 최적의 결과를 가져오는 action 를 알기만 한다면, 현재 최적의 Q값(expected value의 최댓값)을 알게 된다는 것이다. () 자세한 내용은 CS231n 14. Deep Reinforcement Learning에 나와있다!!
많은 RL 알고리즘의 아이디어 뒤에는 bellman equation을 매번 update를 통해 action-value function(Q)를 평가하는 것이 있는데, 이러한 반복을 통해 optimal한 값으로 converge하게 하는 것이 목적이다. 하지만 일반적으로 이 action-value function이 각각의 쌍들을 평가하여 일반화가 되지 못하는 문제(+ 수렴하기 위해 너무 많은 연산이 필요)로 function approximator을 사용한다. 이때 neural network에서는 nonlinear function approximator을 사용하며 Q-network에서는 weight가 인 것을 사용한다.
학습 방식은 다음과 같다. 각 반복(iteration)마다 Bellman equation을 사용하여 mean-squared error을 줄이도록 parameter 를 조정함으로써 Q-network를 학습시킨다. 이때 optimal target value가 을 사용하는 대신 approximate target value 를 이용하며 이때 는 이전 반복에서 얻어진 값이다. 이를 loss function으로 식을 나타나게 되면 다음과 같이 바뀌게 된다.
이때 이 식을 변환시키면 로 표현이 가능하다. 이때 target이 weight에 따라 달라진다는 것을 알 수 있는데 이는 지도학습에서 target이 정해진과 대조된다. 따라서 이전 반복에서 사용한 parameter 를 사용하며 최적화가 된 후 값이 변화게 된다. 이때 두번째 항인 target의 variance는 에 과ㄴ한 식이 아니기 때문에 무시해도 된다. 따라서 이를 미분하면 다음과 같다. 이때 계산 비용을 위해 stochastic gradient를 사용한다.
이 알고리즘은 model-free(emulator의 sample을 바로 이용)하며 off-policy라는 것이 특징이다. 이러한 특징으로 인해 (target)greedy policy 를 학습하는 동시에 (behavior) -greedy policy로 적절한 exploration을 만족하는 behavior 분포에 따라 진행이 된다.(선택)
⭐️⭐️ Training algorithm for DQN (Experience Replay)
- [!]
experience replay: 여러번 사용 가능, random sample→ 상관관계⬇️, behavior 평균적으로 얻어지는 장점으로 이 논문에서 가장 중요한 특징 중 하나 - [!]
별개의 target network: 특정 C번의 update마다 target값을 수정하도록 network를 바꿔 안정적으로 학습이 가능하게 함
기존의 알고리즘이 Q-learning 을 크게 2가지 방법으로 수정한 것이 특징이다!
Experience Replay
experience replay란 agent의 experience를 각 시행마다 저장하는 것으로 로 표현이 되고 이 experience들은 데이터셋 로 나타난다. 이때 replay memory에서 이 데이터셋 에서 특정 개수의 experience를 뽑게 된다. 이 방법은 Q-learning update, minbatch update, experience를 샘플링할 때 사용이 되며 크게 3가지의 장점을 가진다.
- 각 experinece는 여러번 weight update가 가능(
한번 쓰고 기억을 잃는 것이 아니라 여러번 사용) ⇒ 데이터 efficiency - sample을 무작위하게 얻어 상관관계를 없앰 (
연속적인 sample은 강한 상관관계를 가지고 학습에 악영향을 미침-효과X,varinace 증가) - behavior 분포가 이전의 state들에 걸쳐 평균적으로 얻어지게 됨(기존에는 하나를 뽑는 순간, 그 다음 sample에 강한 영향을 줘서 학습에 문제가 생김)
하지만 이러한 방법에도 한계점이 존재하는데, 이 알고리즘이 오직 최근 N개의 experience tuple만을 저장하며, update를 진행할 때 분포 D에서 균일하게 뽑는다는 것이다. 이로 인해 2가지 문제가 생기게 된다
- 중요한 transition에 대해 구별하지 못하고 대체된다 (시간이 지나면서 한정된 tuple의 개수 때문에 중요한 transition이 최근의 transition으로 대체됨)
- 모든 transition에 대해 똑같은 가중치를 주게 되어 중요한 transition을 여러번 뽑을 수 없음
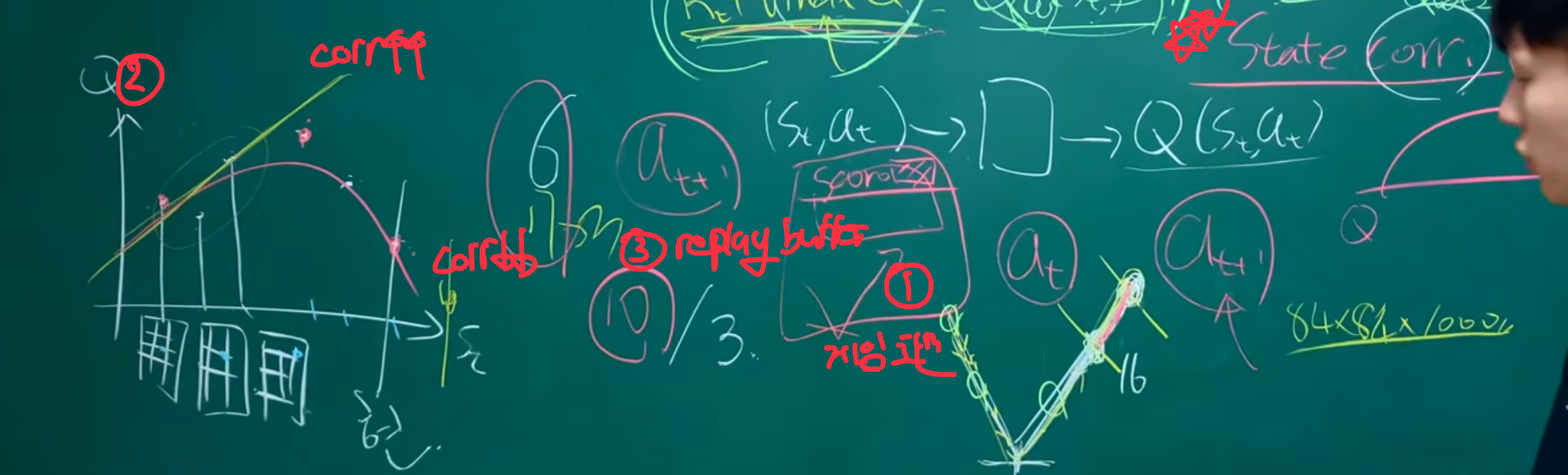 1️⃣ 강한 상관관계(strong correlation)의 문제를 게임화면상에서 보여주는 예시로, 만약 연속적인 n개(
1️⃣ 강한 상관관계(strong correlation)의 문제를 게임화면상에서 보여주는 예시로, 만약 연속적인 n개(correlation⬆️)의 sample들을 가지고 policy를 평가하고자 한다면 전체적인 상황을 모를 뿐더러 사실상 sample 1개를 보는 것과 별반 다를 게 없음. 반면에 random하게 sample을 하면(correlation⬇️) 전체적인 상황을 알 수 있으며, 어떤 상황인지 이해가 가능하여 최적의 policy를 찾는데 도움이 된다
2️⃣ correlation의 정도에 따라 학습이 어떻게 완료되는지(regression이 되는지) 시각화한 그림으로, 평면에 비슷한 State의 값(correlation⬆️)들은 비슷한 Q값을 가지기 때문에 regression이 제대로 이뤄지지 않지만, random한 state 값 (correlation⬇️)들은 무작위한 Q값을 가져 최대로 된 regression이 가능하게 만든다
3️⃣ replay buffer가 존재하며 이 중 n개의 sample을 가지고 update를 진행한다
2. target 에 대해 Q-learning update에 별개된 network 사용
매번 C번의 update마다 기존의 Q network에서 새로운 target network 로 복제하여 target 를 만드는데 사용한다. (유튜브 강의에서 특징적으로 다뤘던 부분!) 이렇게 C번마다 update하지 않고 매번 update하게 될 경우 policy의 값이 변동되게 되며 불안정하게 학습하는 문제가 생긴다. 그렇기 떄문에 C번마다 학습하게 하여 delay를 만들고 일정한 값이 영향을 줄 수 있는 시간을 만들어 변동하는 문제를 줄일 수 있게 한다.
또한 error term을 -1과 1 사이로 clipping하여 (reward에서와 유사) 정규호라를 시켜 알고리즘의 안정성을 증가 시켰다.
알고리즘

Body(본문)
Introduction
- [!] 목표: 일반적인 AI(Generative AI)를 만드는 것!
RL에 있어 agent가 자신이 처한 환경에서 어떻게 최적화가 되는지가 중요하지만 실제 세계의 복잡성 때문에 학습에 어려움이 있었다. 인간과 같은 생물에서는 이를 계층적인 감각처리 기술과 RL의 합작품으로 이를 해결한다. RL에서도 Deep Q-network(DQN)을 통해 고차원의 input도 학습이 가능했으며 atari게임에서 사람들보다 우수한 성능을 보였으며 고차원의 input과 action 사이를 이어 어려운 일에 대해 학습이 가능캐했다.
이 논문의 목표는 일반적인 AI(Generative AI)를 만드는데에 있으며, DQN이 이 목표에 한발짝 가까이 만들었다. 이때 Deep Convolutional Network를 이미지 인식하는데 이용했다. 이를 통해 사람과 같이 인식을 할 수 있도록 만들었다. 또한 이 agent의 목표는 cumulative future reward를 최대화하는 방향으로 action들을 뽑는 것으로 이때 optimal action-value function(Q-function)을 이용한다.
Model (이 논문의 모델에 특이점)
- [!] experience replay + periodically updated target value
- 동일한 모델 → 일반성을 강조
기존의 RL의 문제는 action-value function을 나타내기 위한 nonlinear function approximator가 연속된 sample에 대해 높은 상관관게(correlation)을 가지고 있다는 것이었다. 이에 이 논문에서는 experience replay와 periocally updated target value를 통해 상관관계(correlation)을 줄여 해결했다.
또한 기존 RL의 학습과정에서의 문제는 수많은 state-value들이 존재해 이를 학습하는데 너무 오래걸리고 비효율적이라는 것이었는데, 이 논문에서는 이 큰 규모의 neural network를 학습하기 위해 approximate value function 를 도입해 가 i번째 반복에서 학습이 가능하도록 만들었다. experience replay 구현하기 위해 업데이트 시 에서 샘플들을 뽑아 Q-learning update에 사용한다. 자세한 update 방식은 위에서 설명했으니 생략하겠다.
또한 일반적인 AI(Generative AI)를 만드는 것을 목표로 했다싶이, 서로 다른 atari 게임에 같은 network와 hyperparameter을 이용하여 매우 제한적인 사전지식(prior knowledge) 최대한 실제 환경과 비슷하게 모델을 구성했으며, stochastic gradient descent를 이용하여 학습을 진행했다.
⭐️ Evaluation
- [!] baseline: 기존 atari게임에서의 가장 우수한 RL 모델 & 인간
- [!] t-SNE를 통해 성공적으로 학습했다는 것을 보여줌 ⇒
다른 사람들에게 우리 모델이 제대로 학습했다고 적절한 시각화를 통해 주장(blackbox 문제를 해결) 단순히 성능만으로 모델의 우수성을 입증하는 것이 아닌, 실제로 “학습을 했다“라는 것을 입증하는 것도 어렵지만 좋은 방법인듯 - [!] 같은 게임 내에서 t-SNE를 통해 일반화 능력 및 사람과 비슷한 성과를 냈다는 것을 강조
- 다른 게임들에서도 뛰어난 성적을 냄
DQN을 1) 가장 최고의 성적을 낸 RL 모델과 비교를 했으며 또한 2) 숙련된 인간 게임 실험자를 이용하여 비교했다. 이때 49 게임 중 43게임에서 1) 기존의 RL모델보다 뛰어난 성능을 냈으며, (단일 모델을 사용, 게임마다 추가적 모델 변형X) 2) 숙련된 인간 게임 실험자와 비교할만한 성능을 냈다. (49게임 중 29개 게임에서 인간의 점수에 75%를 달성). 또한 이 논문의 모델에 가장 큰 특징인 experience replay와 periodically updated target을 없앴을 때의 성능과 비교해봤을 때 성능이 악화되는 것을 통해 이 모델에서 위 2가지 방법이 실제 일반적인 성과를 내는데 큰 역할을 할 수 있었음을 강조한다.
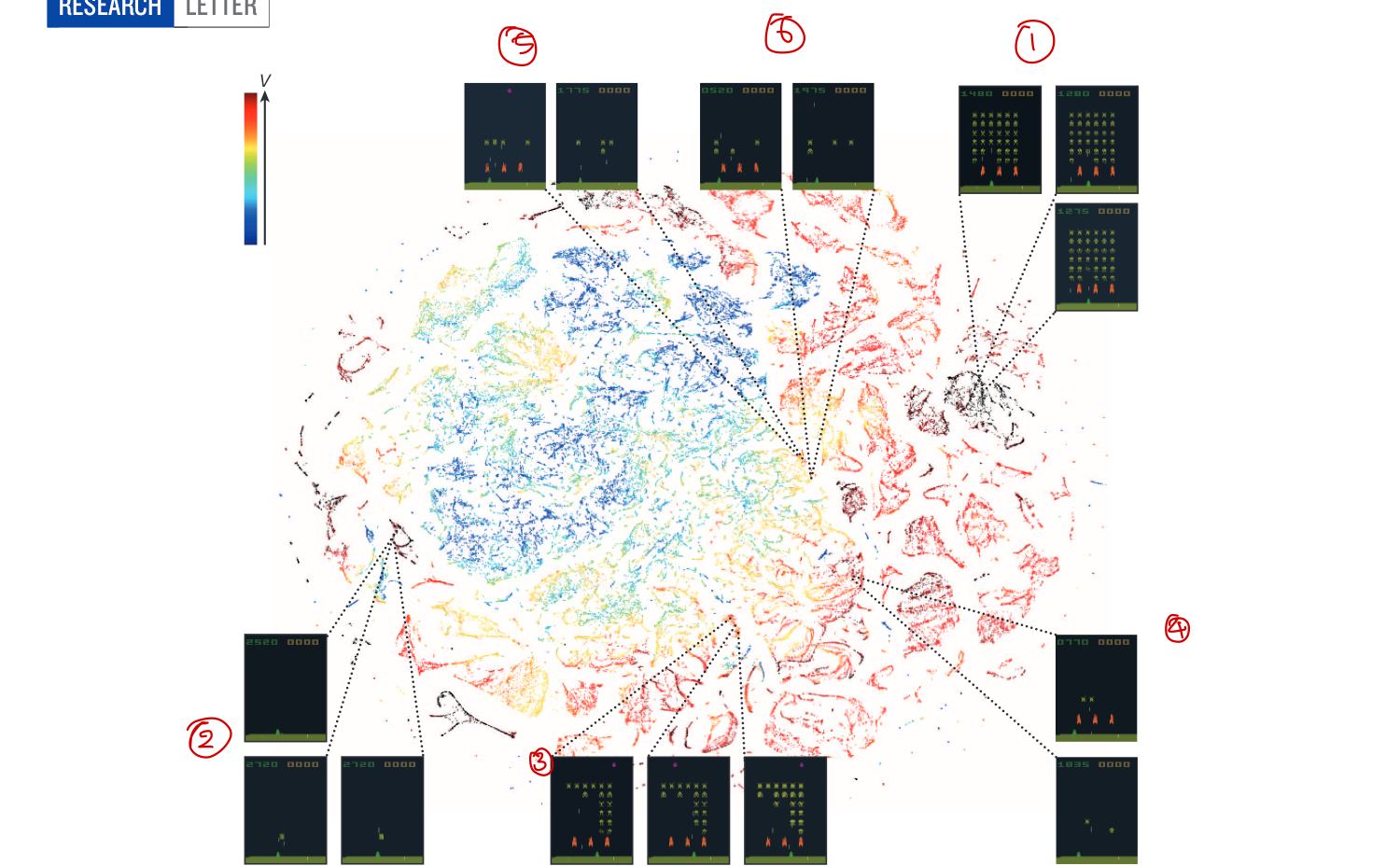 또 고차원 데이터를 2,3차원으로 시각화해주는
또 고차원 데이터를 2,3차원으로 시각화해주는 t-SNE방법을 통해 agent가 성공적으로 학습에 성공했다는 것을 증명했다. 예상한대로 비슷한 state들끼리 모여있었고, 이외에도 우리가 보기에는 서로 달라 보이는 state들이지만 실제 기대되는데 reward가 비슷한 state들끼지 비슷하게 embedding 되어 있다는 것을 확인할 수 있었다. 즉, 네트워크가 제대로 학습을 하고 있으며, 고차원의 input을 받아서 하는 행동에 대한 설명을 가능캐했다. (위 사진에서 4️⃣,5️⃣,6️⃣ 화면들이 우리가 보기에는 서로 달라보이지만 representation상으로 유사하게 나와있는데, 이는 실제로 orange bunker가 실제로 level을 깨는데 도움이 되지 않기 때문이며 1️⃣,2️⃣ d역시 매우 달라보이지만 다 꺨 경우 새로운 화면으로 넘어간 다음 점등을 통해 모델이 제대로 학습하고 있다는 것을 확인 가능)
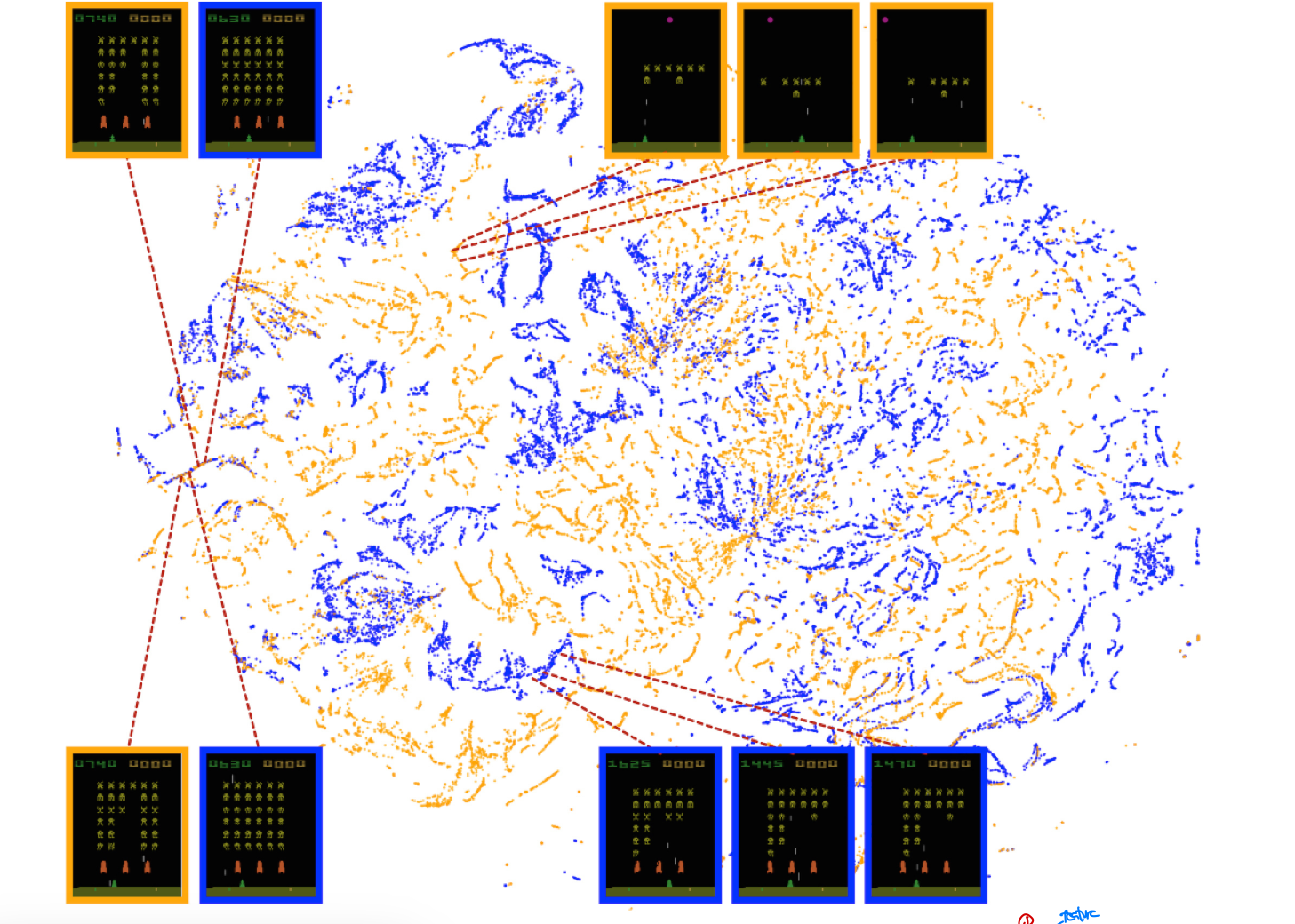 또한 DQN에 의해 학습된
또한 DQN에 의해 학습된 representation들이 policy로부터 생성된 데이터를 일반화(generalization)할 수 있다는 것을 확인할 수 있었다. 위의 사진은 인간이 게임을 했을 떄의 state(주황색)와 DQN이 게임을 진행했을 떄의 state(파란색)을 나타낸 것으로, 1) 사람이 진행한 것과 유사한 학습능력을 가지고 있음을 알 수 있다. 또한 위에서도 언급했다싶이 비슷한 기대되는 reward들끼리 모여있어, 결국 policy로부터 생성된 2) 데이터들이 일반화가 가능해 DQN이 더 넓은데에 사용이 가능함을 시사한다.
더불어 DQN은 매우 다른 환경(서로 다른게임)에서도 뛰어나며 장기적 전략 역시 찾아낼 수 있었다(블록꺠기에서 가장자리를 먼저깨고 위에서 블록을 다 깰 수 있다는 것을 학습함) 그럼에도 불구하고 더 뛰어난 전략들이 요구가 된다는 한계가 있다. (특정 게임은 아예 점수를 얻지 못함)
Conclusion (결론)
이 논문은 DQN을 이용하여 매우 제한적인 사전지식(prior knowledge)를 통해 서로 다른 environment안에 있는 policy들을 성공적으로 학습하는데 성공했다. 또한 생물들이 생물학적으로 학습하는 방법과 이 모델이 학습하는 방법에 몇가지 유사점이 존재한다는 것을 통해 이 모델의 우수성과 타당성의 근거가 되었다
- 기존의 방법과는 다르게
end-to-end RL을 CNN과 같이 적용하여 중요한 feature들을 reward를 통해 학습하고 가치평가(value estimation)을 가능도록 했는데, 이는 유인원의 시각피질안에 representation들이 reward 신호를 통해 학습을 하는 것과 유사하다는 것을 알 수 있다. (보상신호→ feature에 영향) - DQL에서는 RL과 deep network의 결합하는데
replay algorithm이 주요한 역할을 했는데, 실제 생물에서도 기억을 담당하는 해마가 실제 규칙을 찾을 때 사용이 된다는 점에서 유사하며 DQN에서의 value function이 운동 조절 및 보상 신호를 보내는 basal ganglia(기저 핵)과 유사하다.
미래에는 이렇게 생물학적인 동작 방식과 유사한 experience repaly등을 통해 실제 우리 세계에서 일어나고 있는 일과 유사한 문제들을 쉽게 해결할 수 있을 것이라고 예상함(우리 해마도 문제 해결 가능했는데, 이와 동작 방식이 유사한 RL도 가능할 것이다!). 결국 이 논문은 생물학적으로 영감을 받은 이러한 매커니즘을 포함한 DQL 모델이 다양한 여려운 작업들을 해내는 agent를 만들 수 있을것이라고 본다.