그 동안은 지도학습(superviesed learning)들이 무엇이고 어떻게 적용하는지에 대해서 알아봤다면 이제는 비지도 학습(unsupervised learning)에 대해서 알아보고자 한다. 비지도 학습의 가장 큰 특징은 unlabeled data라는 것으로, 지도학습은 x,y(label data)가 존재하는 것과 차이가 있다.
Clustering (K-Means)
비지도 학습의 가장 대표적인 예시로, 비슷한 특징을 가진 데이터끼리 하나의 군집(cluster)을 만드는 것이다. 주로 시장에서 고객을 구별하거나 특징을 잡을 때 많이 사용이 되며서 가장 많이 쓰이는 clustering 알고리즘이 바로K-means clustering이다.
동작방식은 맨 처음에 k개의 점을 잡은 후 이를 cluster centroid라고 두고 각각의 training example을 지나가며 가장 가까운 centroid의 색으로 칠한다.(가장 가까운 centroid의 군집이 된다) 이후 각각의 cluster(군집)의 평균이 되는 곳이 다시 centroid가 되고 이 과정을 하나의 결과로 수렴(converge)될 때까지 반복한다. 참고로 가깝다는 것은 기하학적인 거리가 가깝다는 것을 의미한다
Algorithm
위에서 설명한 것을 수학적으로 나타내면 다음과 같다.
Data : {x(1),x(2),…,x(m)}
Cluster Centroid μ1,μ2,…,μk∈Rn를 무작위하게 초기화
- 주로 centroid μ들을 training set들 중 k개를 뽑아 그 위치가 첫 centroid의 위치가 된다
- k개 만큼 centroid를 잡아야한다
Convergence(수렴)되기 전까지 반복a) 각 점 들을 색칠한다Set: c(i):=argminj∣∣x(i)−μj∣∣2
- 모든 example에 대해서 가장 가까운 centroid를 찾는 것으로, 이 조건을 만족하는 centroid의 색으로 칠해진다
- 참고로 여기서는 기본적으로L2 norm을 사용하며 L2 squared norm으로 사용이 가능하지만 (여기서는 같은 거리를 의미)L1 norm은 사용이 불가하다. (∣∣x∣∣1은 L1 norm을 의미)
b) centroid를 cluster의 중심으로 움직인다For j=1,2,...,k : ,μj=∑i=1m1{c(i)=j}∑i=1m1{ci=j}x(i)
- 특정 cluster이 j인 example x들에 대해서 값들의 평균을 구한다
Convergence
이 알고리즘이 왜 항상 converge(수렴)하는지 알아보자! 이를 위해 cost function을 cluster centroid μ 와 이때의 각 example들이 어떤 cluster에 포함되는지 나타내는 c(assignment) 와 함께 다음과 같이 cost function을 만들 수 있다 J(c,μ)=∑i=1m∣∣x(i)−μc(i)∣∣2
이 cost function은 centroid와 assignment를 알 때 각 example에서 가장 가까운 centroid까지의 거리가 최소가 되는 것을 목적으로 만들어졌다. 이때 각 iteration(반복)마다 K-means 알고리즘은 이 cost function의 값을 줄일 수 있다.이때 cost function의 값은 0보다 작아지지 않지만 값은 항상 감소하므로 언젠가 converge한다는 것을 직관적으로 알 수 있다.
그럼 K는 어떻게 구해야하나요??
직접 해보면서 적당한 K를 구해야합니다!! 비지도 학습에서는 데이터 셋안에 얼마나 많은 cluster(군집)이 있는지 모호할 때가 많다. 좁게 보았을 떄는 여러개지만 관점을 조금만 넓혀도 하나의 cluster라고 생각할 수 있기 때문이다. clustering 사용해야할 목적에 맞추어 k값을 정하는 것이 이상적이다!
K-Means도 local optima에 빠질 수 있다!
local optima에 빠지는 것이 걱정된다면 K-means 알고리즘을 여러번, centroid를 무작위하게 초기화한 뒤 가장 cost function에서의 값이 작은 결과를 택해 사용하면 된다!
EM Alogrithm
Density Estimation
CS231n 13. Generative Models 에서도 짧게 소개되는 density estimation은 확률 변수의 probability distribution(확률 분포)를 추정하는 과정을 말하며 주어진 data sample(표본)들로부터 probability distribution의 형태등을 추정하여 해당 분포를 모델링하는 것을 목표로 한다. 그동안 배웠던 Maximum Likelihood Estimation이 바로 그 예중 하나이다.
예를 들어 비행기 정비를 하는데 이때 중요한 feature를 heat와 vibration이라고 하자. 이때 아래와 같이 분포를 가질 때 빨간색 점이 이상치(anamoly)라는 것을 알기 위해서는 이 example들의 density 혹은 분포를 probability distribution(확률 분포)로 만든 뒤에 빨간색 점이 sample될 확률이 ϵ보다 작은지 확인하면 된다. 이 확률 분포를 모델링한 함수가 p(x)라고 할 때 p(x)<ϵ이면 이상치라고 생각한다는 뜻이다.
기계의 고장이 있는지 매번 anomaly detection을 진행하는 경우나 컴퓨터 보안쪽에서 굉장히 특이한 형태의 트래픽을 발견될 때 자주 사용이 된다.
그렇다면 p(x)를 어떻게 모델링할까?? 특히 L자형과 같이 데이터들이 무작위하게 분포되어 있을 때 어떤 방법으로 모델링을 해야할까? 이렇게 복잡한 분포를 모델링하기 위해 Gaussian model들이 혼합된 경우를 이용한다
Mixture of Gaussians model
이해를 돕기 위해 1차원 예시를 들어보도록 하겠다! 아래와 같이 2개의 Gaussian distribution(G1,G2)가 겹쳐져 있는 overall density가 존재할 때 만약 각각의 점들이 어느 Gaussian distribution에서 왔는지 알고 있다면 GDA를 이용하여 모델을 학습시킬 수 있다. CS229 5. GDA & Naive bayes에 자세하게 나와있다
하지만 문제는 우리가 각각의 점들이 어떤 Gaussian distribution에서 오는지 모른다는 사실이다!latent (hidden/unobserved) random variable z가 있고 x(i),z(i) 분포(distributed)되어 있다고 가정할 때 다음과 같은 식이 성립한다.
P(x^{(i)},z^{(i)})=&P(x^{(i)}\mid z^{(i)})P(z^{(i)})\\ \text{ where } z^{(i)} \sim Multinomial(\phi) &\text{ , }x^{(i)}|z^{(i)}=j \sim N(\mu_{j},\Sigma_{j})
\end{align}$$
즉, 하나의 example이 j번째 Gaussian에서 온 것을 알았을 때 $x^{(i)}|z^{(i)}=j \sim N(\mu_{j},\Sigma_{j})$와 같이 평균이 $\mu$이고 공분산이 sigma인 Gaussian distribution을 따른다는 뜻이다.
GDA와 비슷하지만 3가지의 차이점이 존재한다.
1. z의 개수
여기서는 k개의 Gaussian의 혼합이기 때문에 z가 k개인 반면에, GDA에서는 2개이다.
2. 공분산
여기서는 $\sigma_{j}$를 쓰지만 GDA에서는 covariance matrix $\Sigma$를 사용한다
3. **labeled data의 유무!
GDA에서는 $(x^{(i)},y^{(i)})$ 데이터를 사용하는데 이때 y는 관측된 labeled data인 반면에 여기서는 알지 못하는(latent) data의 z를 사용한다는 점에서 가장 큰 차이를 보인다!**
이렇게 된다면 우리가 latent data z를 알기만 하면 MLE(Maximum Likelihood Estimation)을 통해 해당 분포를 추정이 가능하다. 이때 GDA에서와 같은 형태의 식이지만 다른 점이 바로 y가 아니라 z를 사용한다는 것이다.
$$\begin{align}
l(\phi,\mu,\Sigma)=\sum_{i=1}^m\log P(x^{(i)},z^{(i)};\phi,\mu,\Sigma)\\ \\
\phi_{j}=\frac{1}{m}\sum_{i=1}^m 1\{z^{(i)}=j\}, \mu_{j}=\frac{\sum_{i=1}^m1\{z^{(i)}=j\}x^{(i)}}{\sum_{i=1}^m1\{z^{(i)}=j\}}\end{align}$$
하지만 우리는 실제 z의 값이 무엇인지 모르기 떄문에 이를 적용할 수 없다
## Expectation-Maximization (EM)
---
특정한 값을 얻은 뒤 알고리즘을 통해 추측을 변경해가는 것을 반복하는 #bootstrap 방법을 사용하며 z의 값을 추정하여 MLE 계산을 가능토록 만든다
### Expectation step (E-step)
$w_{j}^{(i)}$를 latent variable z가 j일 확률로 정의한 후 Generative 알고리즘에서 bayes' rule을 이용한 것 처럼 이를 이용해 계산이 가능하도록 바꾼다. 이때 $P(x^{(i)}|z^{(i)}=j)$ 부분은 gaussian density에서 오는 부분이고 $P(z^{(i)}=j)$는 Bernoulli distribution에서 z가 특정 j의 속할 확률를 구하는 부분($\phi_{j}$)이다. ($z \sim Multinomial(\phi)$)
<mark style="background: #ADCCFFA6;">이때 sigmoid function의 height가 곧 $w_{j}^{(i)}$가 되며 각각의 example들이 z가 j일지에 대한 확률이 sigmoid function으로 나타내지기 때문에 $w_{j}^{(i)}$에 모든 수들이 저장되게 된다. 결국 $w_{j}^{(i)}$가 posterior choice(사후 확률), 예시에서는 G1 Gaussian에서 올지 G2 Gaussisan에서 올지 계산하는 역할을 한다. </mark>
### Maximization step (M-step)
앞선 expectation step에서의 결과로 $w_{j}^{(i)}$가 추정이 되기 때문에 이를 이용해 MLE를 사용하면 분포를 모델링할 수 있다. 이때 기존 MLE의 차이점은 $1\{z^{(i)}=j\}$가 $w_{j}^{(i)}$로 바뀌었다는 것이고 이때 $w_{j}^{(i)}=E[1\{z^{(i)}=j\}]$를 의미한다.(indicator function의 평균이 곧 특정 j값의 확률값과 동일) 이를 통해 다시 식을 쓰게 되면 다음과 같다$$\phi_{j}=\frac{1}{m}\sum_{i=1}^m w_{j}^{(i)}, \mu_{j}=\frac{\sum_{i=1}^mw_{j}^{(i)}x^{(i)}}{\sum_{i=1}^mw_{j}^{(i)}}$$
**EM 알고리즘을 학습한 뒤에는 P(x,z)의 density를 알게 되고 $P(x)=\sum_{k}P(x,z)$가 되어 여러개의 Gaussian distribution을 통해 매우 복잡하고 이상한 형태의 distribution도 표현이 가능해진다. 그 결과 $P(x)< \epsilon$ 일 때 anamoly하다는 것을 파악할 수 있다.**
>[!information] **EM-Soft Assignment!**
>
EM algorithm이 k-mean clustering 알고리즘과 유사하지만 차이점이 존재한다. **K-means에는 각각의 지점(example)을 k개의 centroid중 하나로 지정을 하는데 (hard assignment), EM에서는 서로 다른 centroid의 soft assignment를 진행한다.** 즉, K-mean은 하나의 지점에서 여러개의 centroid까지의 거리가 비슷할 때 오직 하나의 centroid의 속하도록 assignment(할당)되지만 EM은 가장 가까운 centroid를 뽑는 것이 아닌 어느 분포에 들어가는 것인지 확률을 이용해 평균을 구한다는 점에서 차이가 존재한다.
>[!summary] EM 알고리즘 복습!
>
>$w_{j}^{(i)}$는 각 example $x^{(i)}$가 k개의 Gaussian distribiton 중 하나인 $\mu_{j}$에 할당될(assigned) 정도나 확률을 뜻한다. 결국 **얼마나 강하게 특정 example이 특정 gaussian distribution에 들어갈지 알려주는 변수가 된다**. 예를 들어 가까운 G1 distribution에는 0.8의 확률로, 먼 G2 distribution은 02.의 확률로 각 분포에 들어갈 확률을 정해주는 역할을 한다.
>참고로 이런 식으로 w를 구하고는 있지만 latent variable z가 무엇인지는 아무도 모른다. **그렇기 때문에 w를 이용해 특정 example이 특정 distribution에 들어갈 확률을 E-step에서 구한 뒤, M-step에서 모든 example들을 본 뒤 weight w를 이용해 Gaussian distribution을 바꾸어 성능을 높인다**.
## Jensen's inequality
---
지금까지는 직관적이고 간단하게 EM 알고리즘이 어떻게 converge되고 학습하는지 알아봤다면 여기서는 P(x)를 최대화하려고 할 때, MLE에서 하려는 목표가 곧 EM과 똑같다는 것을 알아보고자 한다. $P(x,z;\theta)$ 가 주어졌을 때 $argmax_{\theta} \Pi^m_{i=1}P(x^{(i)};\theta)$ 를 하는 것이 EM의 목표라는 것을 더 수학적(rigorous derivation)으로 증명하여 EM 알고리즘이 합리적인 알고리즘이라는 것을 알아내려고 한다!
먼저 **f를 #convex function(오목)라고 할 때 $f''(x)>0$의 성질을 만족시키며, X를 random variable이라고 한다면 $f(E[X])≤E[f(X)]$가 성립**한다는 것이 #Jensen_inequality의 내용이다.
![[Pasted image 20240328145524.png]]
또한 f가 strictly convex하다면 ($f''(x)>0$), $E[f(x)]=f(E[X]) <=> X \text{ is a constant}$이 성립한다. 이때 **strictly convex하다는 뜻은 직선이 존재하지 않는다는 말이며 이럴 경우 두 함수가 같아지는 경우는 X가 random variable이 아니라 하나의 상수(constant)인 경우(random variable이 항상 같은 값을 갖음) 밖에 없다**는 것을 의미힌다. 이때 X의 값이 상수(constant)하다는 말을 정확히 표현하면 $X=E[X] \text{ with probability 1}$ 라고 나타낼 수 있다. (X가 100%의 확률로 E[X] 값, 즉 상수를 갖는다!)
하지만 우리가 사용할 때에는 #concave function을 사용하기 때문에 위에서 설명한 내용을 바꾸면 다음과 같이 바꿀 수 있다. 즉 우리는 Jensen's inequality의 concave 형태를 사용한다.$$\begin{align}
&\text{Let f be a concave function and X is a random variable } (f''(x)<0) \\
&f(E[X])≥E[f(X)] \\
&\text{Further if } f''(x)<0 \text{ then , } E[f(x)]=f(E[X]) <=> X \text{ is a constant}
\end{align}$$
### Density Estimation
이제 $P(x)$를 구해보자!(density estimation) **우리의 목표는 모델을 $\theta$로 표현하여 이 $\theta$에 대한 log likelihood의 식을 구한뒤 MLE를 이용해 가장 실제 분포와 유사하게 만드는 $\theta$를 찾아 모델링하는 것이다!**
- 우리는 $P(x,z; \theta)$인 모델을 가지고 있다.(여러가지 parameter들 대신에 $\theta$를 이용해 표현!).
- 이때 우리는 x에 대해서만 알고 있고 이에 따라 training set $\{x^{(i)},\dots,x^{(m)}\}$을 가진다.
- parameter $\theta$에 대해 log likelihood 식을 쓰면 다음과 같다
$$\begin{align}
l(\theta)=&\sum_{i=1}^m\log { P(x^{(i)};\theta) } \\
=&\sum^m_{i=1}\log \underbrace{ \sum_{z^{(i)}}P(x^{(i)},z^{(i)};\theta)}_{ \text{x의 각 z분포에서의 확률을 더하면 같은 값! }} \\
&*\text{want: }argmax_{\theta}\text{ }l(\theta)
\end{align}$$
이후 우리가 하고자 하는 것은 EM알고리즘을 통해 parameter $\theta$의 MLE를 구하는 것이다?
![[Pasted image 20240329110136.png]]
![[Pasted image 20240329105553.png]]
![[Pasted image 20240329111725.png]]
{kind=link}
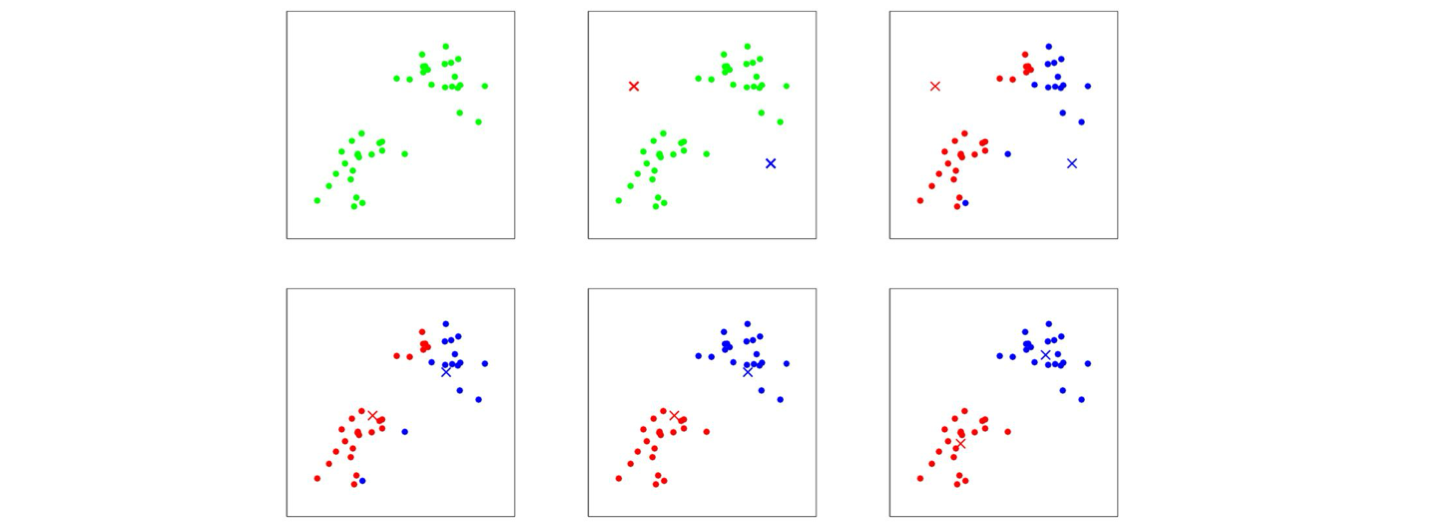 동작방식은 맨 처음에 k개의 점을 잡은 후 이를 cluster centroid라고 두고 각각의 training example을 지나가며 가장 가까운 centroid의 색으로 칠한다.(가장 가까운 centroid의 군집이 된다) 이후 각각의 cluster(군집)의 평균이 되는 곳이 다시 centroid가 되고 이 과정을 하나의 결과로 수렴(converge)될 때까지 반복한다. 참고로 가깝다는 것은 기하학적인 거리가 가깝다는 것을 의미한다
동작방식은 맨 처음에 k개의 점을 잡은 후 이를 cluster centroid라고 두고 각각의 training example을 지나가며 가장 가까운 centroid의 색으로 칠한다.(가장 가까운 centroid의 군집이 된다) 이후 각각의 cluster(군집)의 평균이 되는 곳이 다시 centroid가 되고 이 과정을 하나의 결과로 수렴(converge)될 때까지 반복한다. 참고로 가깝다는 것은 기하학적인 거리가 가깝다는 것을 의미한다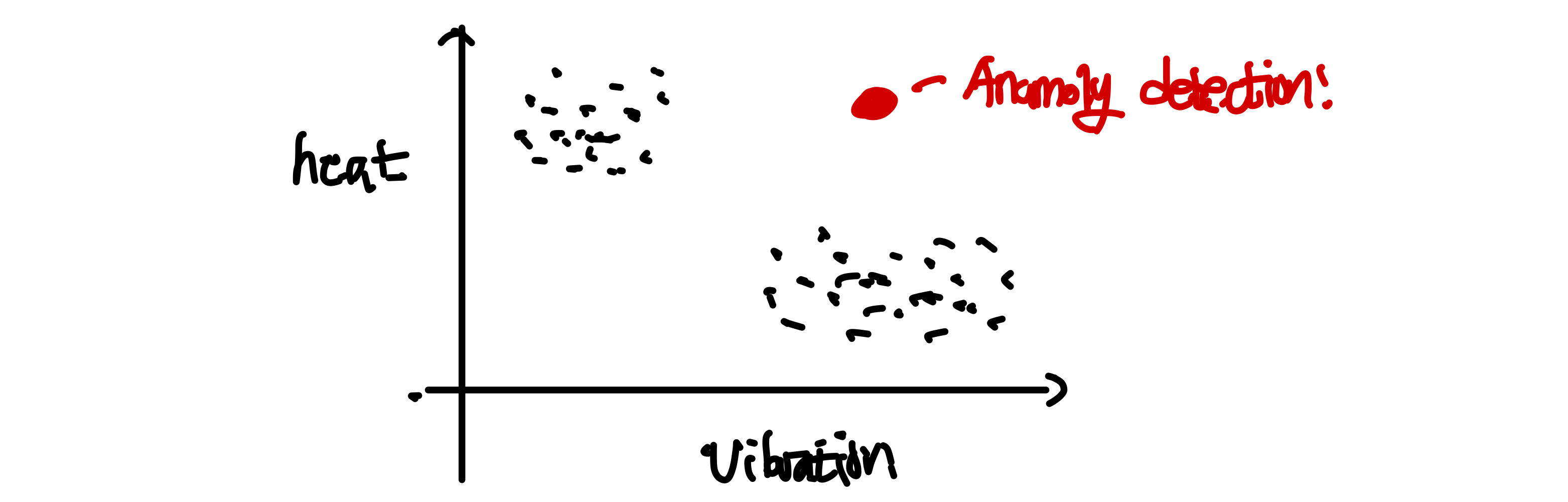 기계의 고장이 있는지 매번 anomaly detection을 진행하는 경우나 컴퓨터 보안쪽에서 굉장히 특이한 형태의 트래픽을 발견될 때 자주 사용이 된다.
기계의 고장이 있는지 매번 anomaly detection을 진행하는 경우나 컴퓨터 보안쪽에서 굉장히 특이한 형태의 트래픽을 발견될 때 자주 사용이 된다.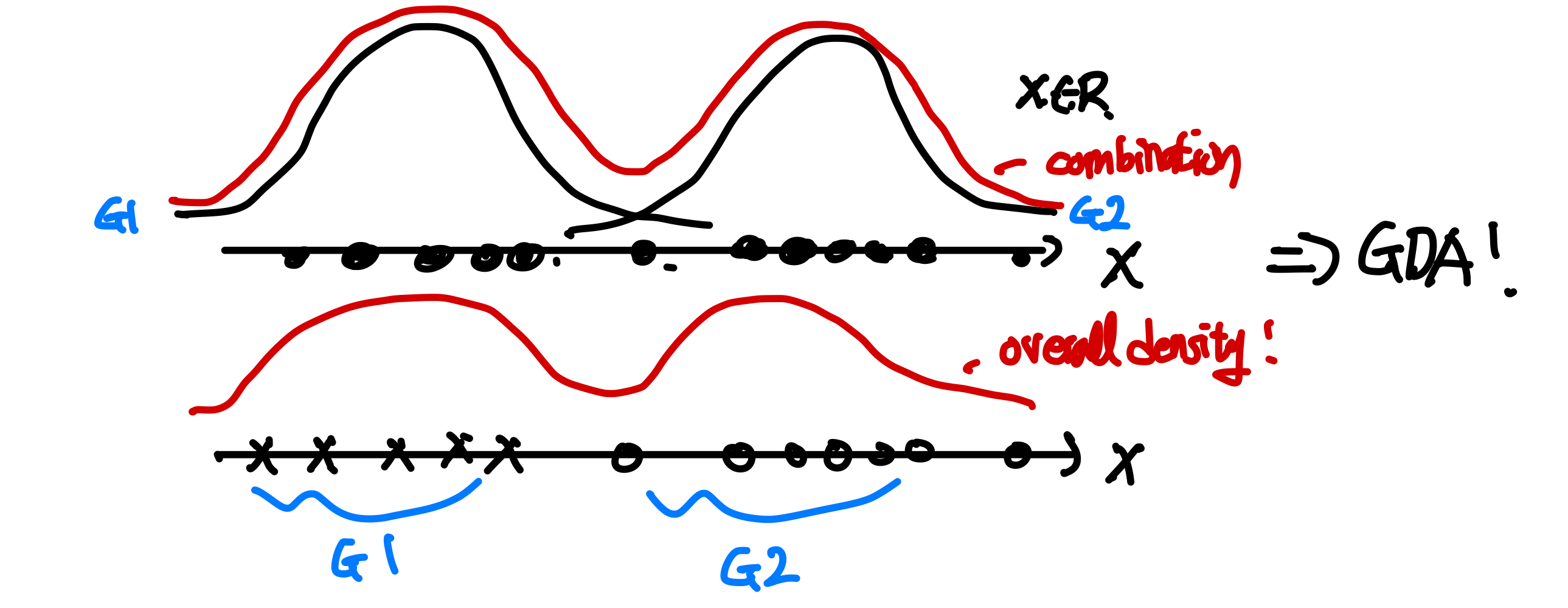 하지만 문제는 우리가 각각의 점들이 어떤 Gaussian distribution에서 오는지 모른다는 사실이다!
latent (hidden/unobserved) random variable z가 있고 분포(distributed)되어 있다고 가정할 때 다음과 같은 식이 성립한다.
하지만 문제는 우리가 각각의 점들이 어떤 Gaussian distribution에서 오는지 모른다는 사실이다!
latent (hidden/unobserved) random variable z가 있고 분포(distributed)되어 있다고 가정할 때 다음과 같은 식이 성립한다.