{kind=link}
많은 사람들이 deep learning model의 내부에서 어떤 동작을 하고 있는지 모르기 (black box effect)때문에 deep learning으로 도출한 결과를 믿지 못하는 경우가 있다. 그렇기 때문에 deep learning 내부에서 어떤 동작을 하고 있는지 시각화하여 사람들로 하여금 deep learning의 결과를 믿게 하고 이 동작과정에 대한 이해를 돕는다
layer에 위치에 따라 어떻게 시각화할 수 있을까
하나의 일반적인 image가 들어왔을 때 각 layer에서는 어떻게 모델이 돌아가고 어떤 반응을 하는지 알아보자!
1. First layer
image를 sliding하면서 inner product한 값이기 때문에 filter가 무엇을 보고 있는지 감각을 얻을 수 있음 - filter의 learned weight를 시각화한 결과 - wx(weight와 input data의 내적)을 통해 filter 값이 정해지는데 내적할때 maximally activation하게 만드는 것이 weight! 그렇기 때문에 이 weight를 visualizing하여 이해가능! 하지만 2번째 layer부터는 1번째 layer의 각 부분이 어떤 것을 의미하는지 알 수 없기 때문에 무엇이 2번째 layer값을 maximally activate하게 만들었는지모름 - 즉, maximally acivation하게 만든게 weight가 아니기 떄문에 시각화해도 알기 힘듦(activation pattern을 모름!) - weight를 보고 알 수 있는 것이 많지 않기 때문에 바로 image로 바꾸기 힘듦 - 직접 input image에 연결되어 있지 않기 떄문에 좋은 직관을 주지 못함
2. last layer
각각의 input image를 4096dim feature vector로 저장 여러가지 이미지를 network로 실행하여 feature vector들을 모을 수 있다!
Nearest Neighbors CS231n 1. Image Classification
마지막 feature vector을 이용하여 Nearest Neighbors를 계산하고 이를 통해 마지막 layer에는 실제 input image와 semantic content가 비슷한 사진을 도출할 수 있다는 것을 알 수 있다.
- 1강에 Image Classification에서는 pixel space에 대해 NN을 진행했기 때문에 픽셀 자체는 유사하더라도 실제 이미지와는 다른 경우가 많음
- feature space에서 NN을 할 경우 pixel로 봤을 떄는 다르지만 학습을 거친 feature space는 유사하기 때문에 semantic content가 비슷하다고 볼 수 있음!
feature space도 모델 내에서 중요한 부분을 담당하고 있다는 것을 시각적으로 알 수있음
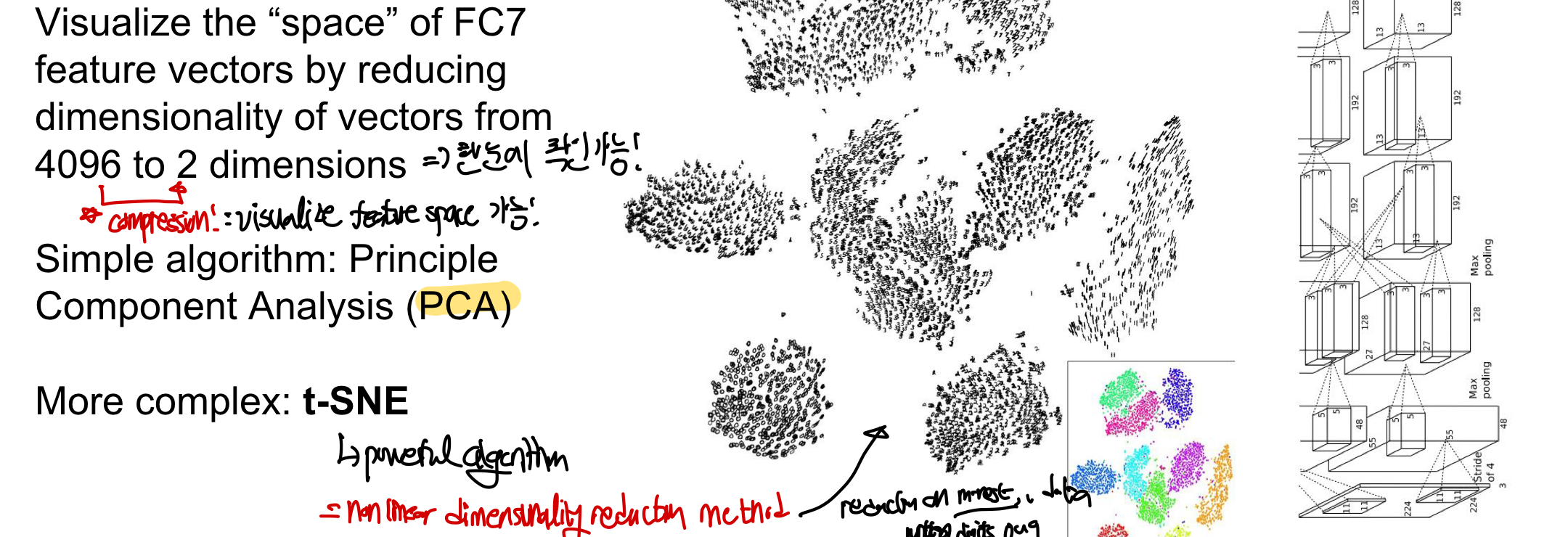
Dimensionality Reduction CS231n 6-3. PCA & Whitening
마지막 layer의 4096dim feature vectore을 2차원으로 압축하여 feature space를 visualize 가능!
- PCA(Principle Component Analysis)를 이용해 시각화 가능
- t-SNE: 더 강력한 non-linear dimensionality reduction 방법을 통한 군집화 가능
- image의 orignial pixel을 가져와 차원축소버전에 맞게 2D coordinate에 위치시킴
- 마지막 feature vector을 각 이미지마다 모아 grid 각각의 위치에 어떤 이미지가 나타났는지를 표현 가능
3. Visualizing Activation(intermediate)
intermediate layer의 activation map이 interpretable 한 경우가 있음 activation map: activation volume의 한 slice로 activation했다는 뜻은 그 부분의 feature가 모델에서 중요하고, classification의 영향을 미치는 부분이라는 것을 알 수 있음 intermediate layer가 무엇을 보고 있는지 알 수 있는데 대부분의 값을 이미지를 제대로 인식하지 못하고 noisy처럼 보이지만 특정 부분이 activation되어 있었다 = 사람의 얼굴을 잘 인식하는 neuron이 중간 layer에 존재!
neuron값에 어떤 image 부분이 영향을 미칠까(뉴런입장)
내부에서 computation이 어떻게 동작하는지 모르겠고 믿을 수 없어? 알려줄게~(다양한 고정 입력 이미지에 대해서 시각화) 즉, train network가 어떤 computation을 하는지 이해하게 만들어주는 도구가 됨 실제로 network가 이미지의 중요한 feature을 이용해 계산을 한다는 것을 입증해주고 각각의 layer의 neuron마다 저마다의 학습을 통해 image를 classify할 수 있다는 것을 알려주고 있다.
1. Maximally Activation Patch(뉴런이 어디를 보고 있냐)
한 neuron이 layer에서 image의 어떤 feature을 보고 있는지 시각화
input image에서 maximum activation의 결과를 가져오는 patch가 어디인지를 확인하여 visualizing
= 즉, neuron이 maximum activation되는 image의 부분을 보고 있다는 것은 image에서 어떤 feature을 중점적으로 보고 있는지와 같다
확인 방법
1. layer을 정하고 그 안에서 시각화할 channel을 뽑는다
2. 많은 image를 network를 통해 학습시키고 내가 선택한 layer에서 feature들을 저장
3. 내가 선택한 layer, channel에서 maximal activation을 보이는 image patch를 시각화!
- 즉, maximal activation을 보이는 image patch 부분을 input image set에서 그 patch 부분을 가져와 시각화해서 어떤 feature을 보고 있었는지를 알 수 있게 만드는 방법
layer이 깊어질 수록 receptive field가 커지기 때문에 좀 더 추상화되고 전체적인 물체 인식이 가능해진다(사람의 눈 → 사람의 얼굴)
반면에 layer이 낮을 수록 단순한 형태만을 구분할 수 있다.(원, 모서리, 사람의 눈)

2-1. Occlusion Experiment
input image의 어떤 부분(pixel)이 network의 classification decision을 중점적으로 영향을 미치는지를 알아봄!(by masking with mean pixel value)
확인방법
1. image를 CNN에 넣기 전에 일부분을 mean pixel value로 mask한 뒤에 input으로 넣는다
2. mask된 image의 예측된 확률을 구하고 이 과정을 반복한다
3. mask한 것으로 인해 network의 score가 급격하게 바뀌었다면 이 부분이 사진에 매우 중요한 부분이라는 것을 알 수 있다.
- mask된 것으로 인해 image를 같은 category와 비교하여 예측한 결과 확률이 낮으면 중요한 부분!
- 확률이 높으면 없어도 되는 부분이기 때문에 중요하지 않다는 것을 알 수 있음
실제로 확률의 분포를 시각화하면 사람이 생각하기에 이미지의 중요한 부분과 매우 유사하다는 것을 알 수 있고 이로 인해 network가 실제로 image의 중요한 부분(feature)을 알아낼 수 있다는 것을 알 수 있음

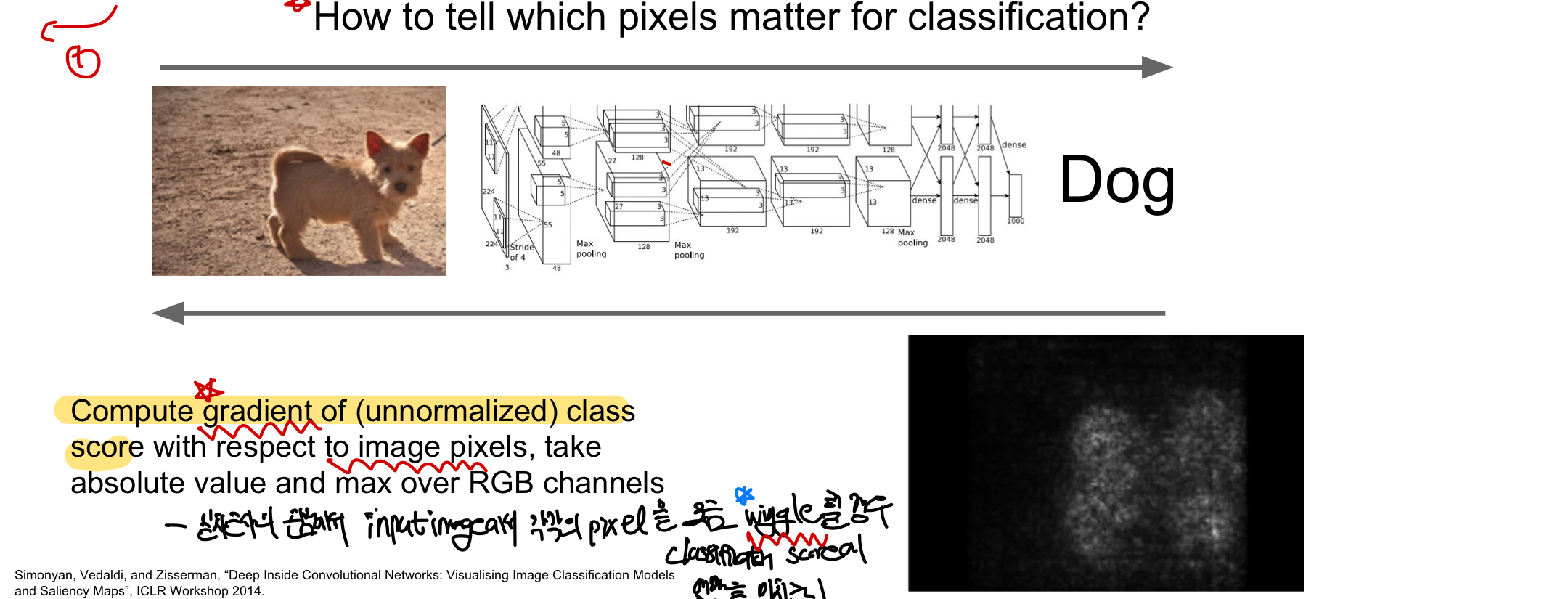
2-2. Saliency Map
어떤 pixel이 classification problem에 중요한 역할인지 알아보는 것!(by gradient with pixel값 wiggle) image pixel에 대해 class score의 gradient를 계산해서 이를 visualize함! - 일차근사 관점에서 input image에서 각각의 pixel을 wiggle(조금 움직임)할 경우 classification score에 어떤 영향을 미치는지 확인 - 주로 image에서 중요한 feature이 object가 될텐데, 이 방법을 통해 시각화하면 일종의semantic_segmentation 이 가능함CS231n 11. Detection & Segmentation - data를 label하지 않아도 물체의 형태를 알아낼 수 있지만 성능이 그렇게 좋지 않음 - 특정 알고리즘과 연결하면 object segment 가능
왜 gradient를 계산하면 이 pixel이 classification에 중대한 영향을 미치는지 알 수 있을까?
A: gradient값이 크면 해당 pixel이 모델 예측에 큰 영향을 미치는 것으로 해석 가능하며, 이 픽셀이 class를 예측하는데 중요한 역할을 미친다는 것을 알 수 있음(픽셀의 값이 조금만 변해도 모델의 큰 변화가 나타는 경우=gradient가 큰 경우) 참고로 이미지의 중요한 부분이 꼭 gradient가 크지 않으며, gradient가 크다고 해서 중요하는 의미는 아님! 단지 그 픽셀에 민감하기 때문에 classification에 중대한 영향을 미치는 것 뿐이며 gradient가 큰 부분이 대체적으로 이미지의 중요한 feature을 담는 경우가 많을 뿐이다. ⇒ 좀 더 정확한 이미지의 중요한 부분을 찾기 위해서 Grad-CAM를 사용할 수 있음(gradient 정보를 활용하여 특정 class를 예측할 때 어떤 부분에 주의를 기울였는지 확인)

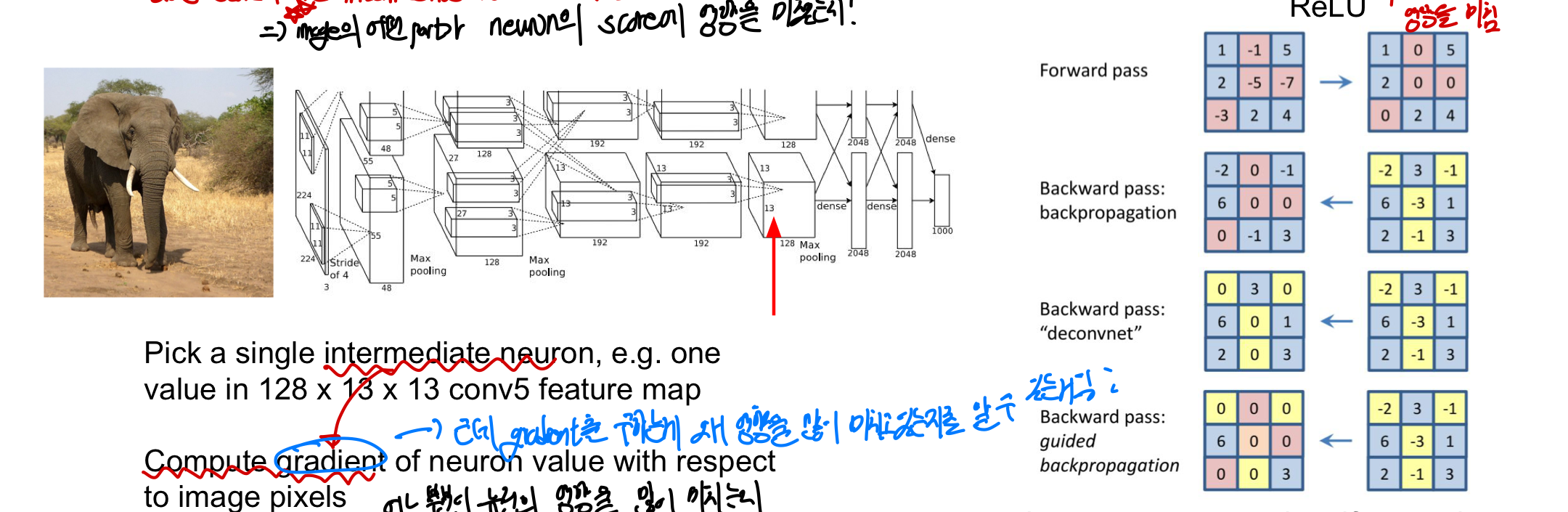
3. Intermediate features via backprop
image의 어떤 part가 중간 layer에 있는 neuron의 score에 영향을 미쳤는지! (intermediate layer도 다 의미가 있어~ 특정한 feature을 인식하는데 이래도 network를 안믿을거야???)
←> class score가 아닌 intermediate neuron을 뽑음! : 밑에 사진에서도 중간 layer에서 어떤 pixel을 보고 있는지 시각화해주고 있음
확인방법
1. intermediate layer에서 하나의 neuron을 뽑음
2. 이 neuron 값의 gradient를 input image pixel에 관해서 계산함
backpropagation 과정에서 Relu함수의 양의 값만 진행하고 음의값을 버리게 된다면 더 깨끗한 이미지를 얻을 수 있다

어떤 input이 들어와야 neuron이 activate할까
이전까지는 fixed된 input image가 neuron값에 어떻게 영향을 미쳤는지 알아봤다면 이제는 어떤 input이 들어와야 neuron이 activate 할수 있는지 알아봄(입력이미지가 일반적인 경우)
1. Gradient Ascent(visualizing features)
neuron을 maximally activate 시키는 synthetic image(합성된 새로운 이미지)를 만들기 위한 방법!
filter의 weight는 고정되어 있고 오직 input image의 fixel만 바뀌는 것이 특징
- maximum score을 가지는 neuron vaue의 argmax(최댓값을가질때의 index) & regularizer(특정 이미지에 overfitting 되는 것을 막음)으로 이루어져 있음
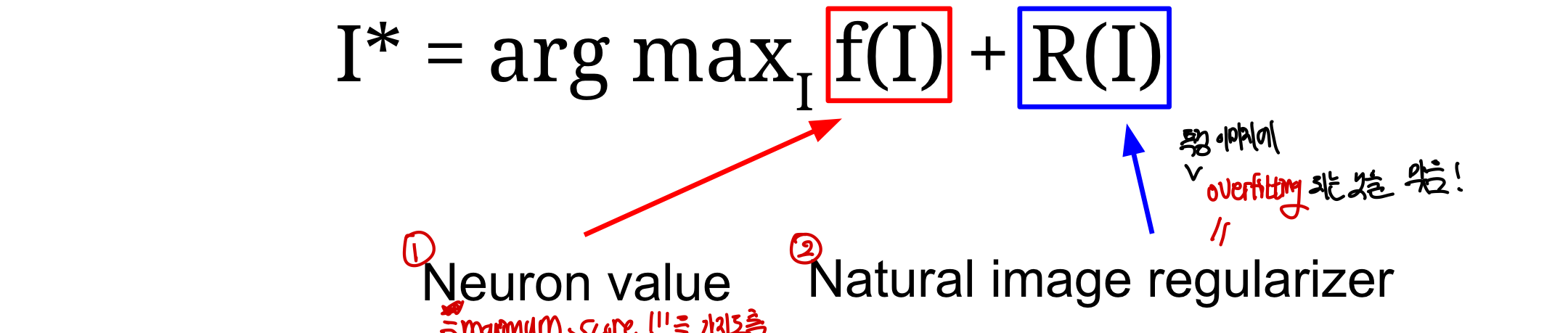
작동방식(1. Neuron Value)
-
- image를 모두 0으로 초기화해둠
- Forward하여 현재 image의 score을 구한 뒤 backprop을 통해 image pixel과 관련하여 neuron의 gradient값을 구함
- 이미지에 대해 small update를 진행(with gradient ascent)
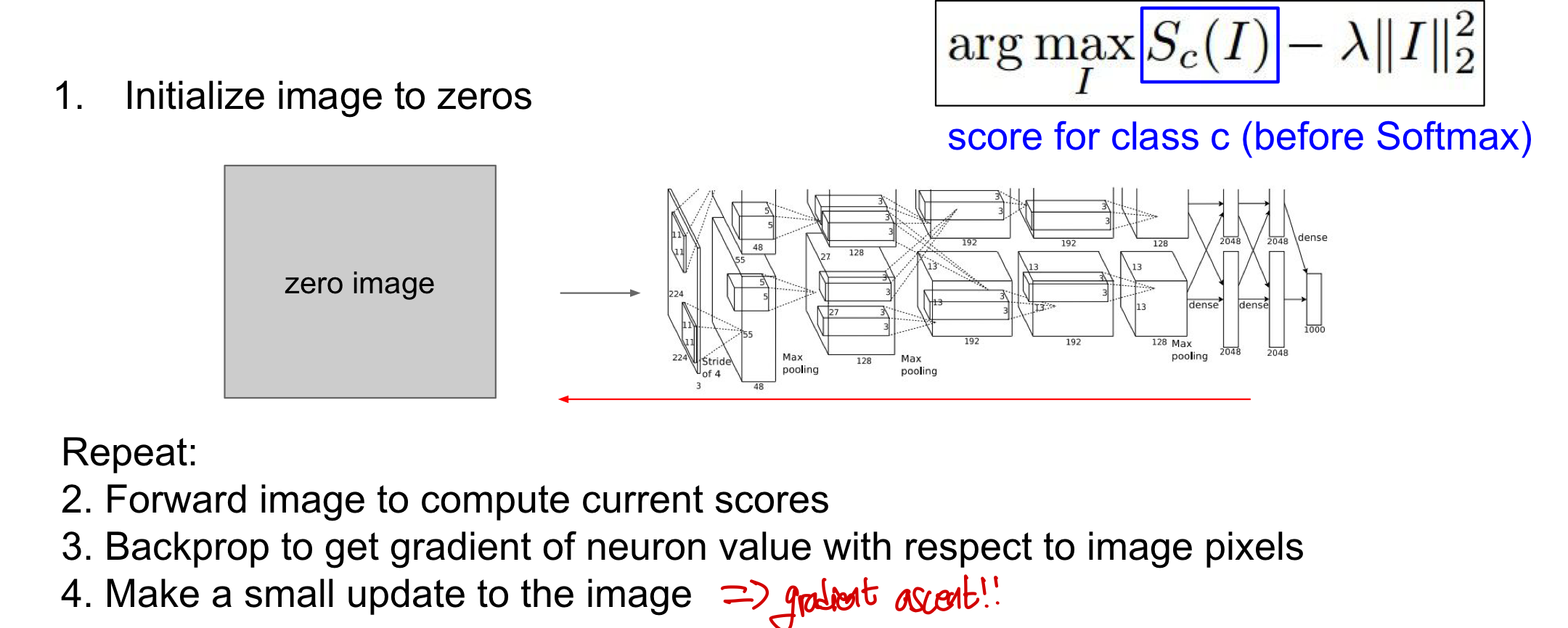
만약 regularizer이 없다면 어떻게 될까?
A: 모델은 score을 최대화 시키는 이미지를 얻게 되지만 그 형태는 우리가 이해하지 못함(random noise) 우리가 network가 어떻게 결정을 내리는지 확인하고 싶을 때 실제 이미지처럼 자연스럽게 만들기 위해 regularizer를 추가! ——→ 이 regularizer의 성능을 더 발전시켜서 visualize 성능을 높이자!!
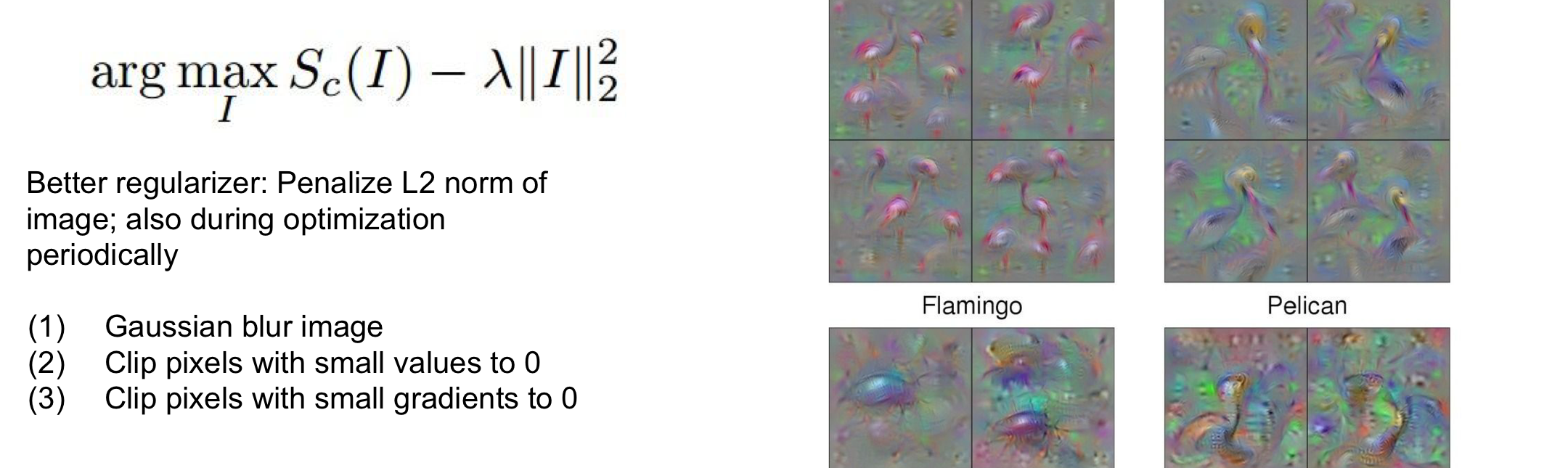
Regularizer 단계에 따른 변화(2. Regularizer)
CS231n 2-3 Linear Classification(Regularization) CS231n 7-2. Evaluation & Regularization
1. Simple regularizer( penalizedL2): 새롭게 생성된 image에 대해 L2 regularization 진행
- 즉, 특정 물체(ex:덤벨)의 score을 최대화시키는 이미지를 생성하고 이떄 regularizer 영향으로 natural한 image가 생성되는 것임!!
 2. penalized L2를 optimization을 할때도 진행: intermediate neuron들도 L2 regularization 진행
←> 전에는 생성된 output image에 대해서만 진행했지만 이제는 그 사이에도 진행하게 됨
- 작은 value와 작은 gradient를 갖는 pixel을 0으로 만들어 더 매끈한 image를 만들어줌
- 중간 neuron이 무엇을 찾고 있는지 알 수 있음!
- Maximally activating Patch와 유사하지만 겨기서는 주어진 input에서 가장 큰 부분을 찾았고 여기서는 가장 activation이 크게 만들게 하는 이미지를 생성
- layer가 점점 깊어지면서 더 많은 receptive field를 가지기 때문에 정교한 부분까지 시각화 가능
- intermedate neuron 값이 maximize하게 만들어주기 때문에 어디를 보고 있는지 확인 가능!
2. penalized L2를 optimization을 할때도 진행: intermediate neuron들도 L2 regularization 진행
←> 전에는 생성된 output image에 대해서만 진행했지만 이제는 그 사이에도 진행하게 됨
- 작은 value와 작은 gradient를 갖는 pixel을 0으로 만들어 더 매끈한 image를 만들어줌
- 중간 neuron이 무엇을 찾고 있는지 알 수 있음!
- Maximally activating Patch와 유사하지만 겨기서는 주어진 input에서 가장 큰 부분을 찾았고 여기서는 가장 activation이 크게 만들게 하는 이미지를 생성
- layer가 점점 깊어지면서 더 많은 receptive field를 가지기 때문에 정교한 부분까지 시각화 가능
- intermedate neuron 값이 maximize하게 만들어주기 때문에 어디를 보고 있는지 확인 가능!

Multimodality
regularizer을 바꾸지 않고 input pixel을 최적화하여 score을 구하는 것이 아니라 FC6 representation을 최적화하는 방법!
- 같은 category(label)에 속하지만 다른 appearance(pixel에서의 차이)의 image를 한데 모아 image 생성가능
- feature map에 대해서 최적화하기 떄문에 semantic으로 유사한 것들을 모을 수 있음!
#multimodality: 하나 이상의 데이터형식에서 정보를 처리하거나 생성하는 능력(pixel간에 유사점이 없는 사진을 같은 label로 묶게 만듦)
- ex: 이미지 캡션(이미지+텍스트 모델리티), 옴성 번역(음성 입력을 텍스트로 변환하고 텍스트를 다른 언어로 번역)
이 방법을 통해 더 정교하고 최적화된 synethised input image를 생성하는 것이 가능해짐(by FC6 최적화 with semantic..)


2. Fooling Images
Gradient를 이용한 방법과는 다르게 새로운 이미지를 만드는 방법!
동작 방식
1. 임의의 이미지를 고른 후 임의의 class를 뽑음
2. 임의의 이미지를 임의의 class에 대해 maximize한 score값을 얻도록 image를 수정
3. network가 바보가 될때까지 반복!(똑같다고 생각할 때까지)
ex) elephant 사진을 가지고 코알라와 비슷하도록 이미지를 수렴(생성)한다
 우리가 판단하기에는 두 사진이 같아 보이지만 network 입장에서는 서로 다른 그림으로 판단
그래서 뭘 말하고자 하고 싶은지는 잘 모르겠음
우리가 판단하기에는 두 사진이 같아 보이지만 network 입장에서는 서로 다른 그림으로 판단
그래서 뭘 말하고자 하고 싶은지는 잘 모르겠음
Style transformation
DeepDream
특정 neuron의 값을 최대화시키는 image를 synthesize(생성)하는 대신에 network내에 특정 layer의 neuron activation을 amplify!(증폭!)
동작방식
1. Forward: 고른 layer에서 activation을 계산
2. 고른 layer에서의 gradient를 activation value값으로 저장
- 해당 layer에 어떤 특징이 있던지간에 , 이 특징을 가지고 gradient를 계산하면 네트워크가 뽑아낸 특징들을 증폭시키는 역할을 함
- 이전에는 특정 neuron(양수의 gradient를 가지는 뉴런)을 최대화시켰다면 지금은 neuron activation을 증폭시킴(모든 뉴런값을 확대)!
3. Backward: 이미지에 대해서 gradient를 계산하고 image를 업데이트 한다
특정 layer을 선택해서 계속하여 이 layer의 모든 뉴런 값들 amplify하여 계속 학습시켜 visualize한다면 별의 별 그림들이 합성된 그림들을 얻게 됨
- 특정 하나의 물체만 얻는 것이 아닌 (Gradient ascent regularizer에서 아령으로 이루어진 사진) layer에 있는 모든 뉴런들을 amplify했기 때문에 각양각색의 물체를 얻게 됨
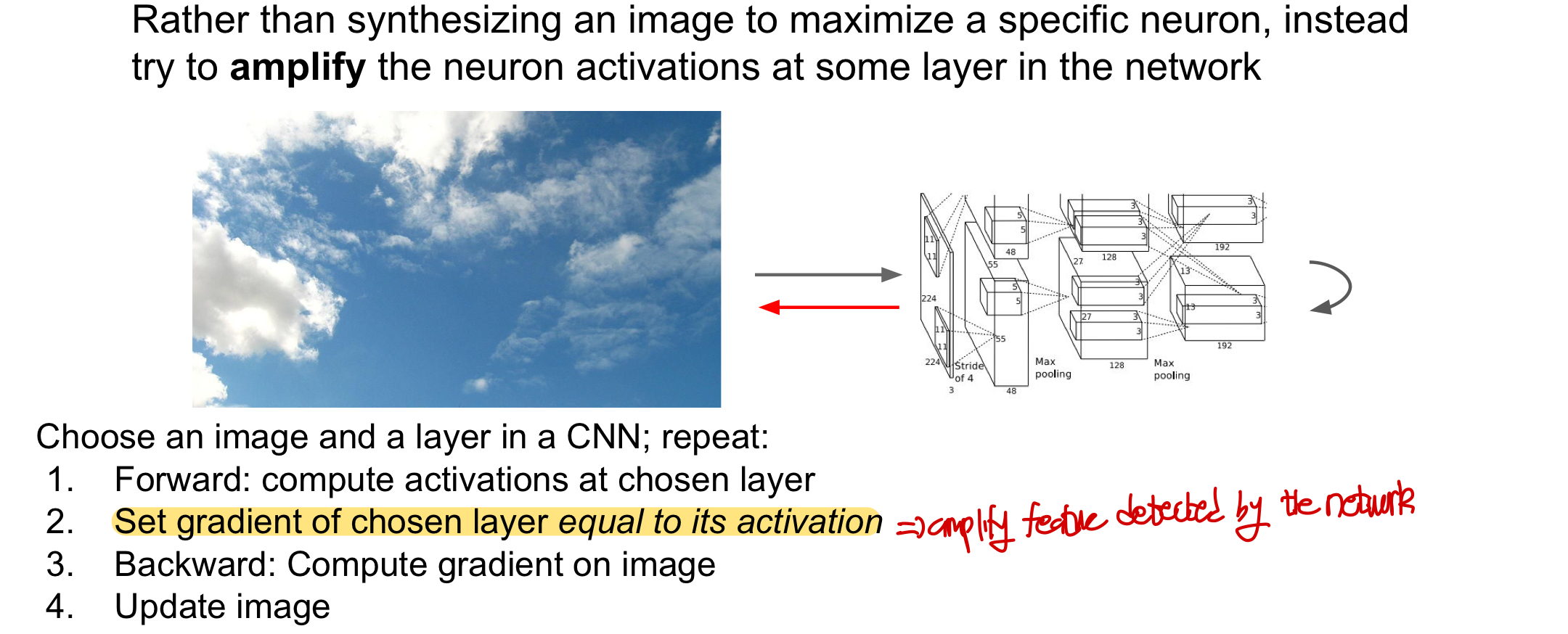
 위의 사진은 깊은 layer을 뽑았을 때의 결과이고 이보다 낮은 layer 같은 경우는 선이나 물결등 섬세하지 않고 단순한 패턴들이 나타남
위의 사진은 깊은 layer을 뽑았을 때의 결과이고 이보다 낮은 layer 같은 경우는 선이나 물결등 섬세하지 않고 단순한 패턴들이 나타남
Feature Inversion
이미지에 대해서 CNN을 통과한 후의 feature vector을 받아 feature vector과 일치하고 자연스러운 새로운 image를 찾음
- record feature value → reconstruct the image
- 이를 통해 network가 어디를 집중적으로 보고 있는지, 어떤 부분이 여러 layer에서 capture 됐는지 알 수 있음
동작방식
1. 주어진 feature vector와 새로운 image의 feature 사이의 거리(차이)가 최소가 되도록 만듦
2. 이때 인접한 pixel간의 차이를 penalize하는 Total Variation Regularizer을 이용하여 spatial smoothness를 만들어냄
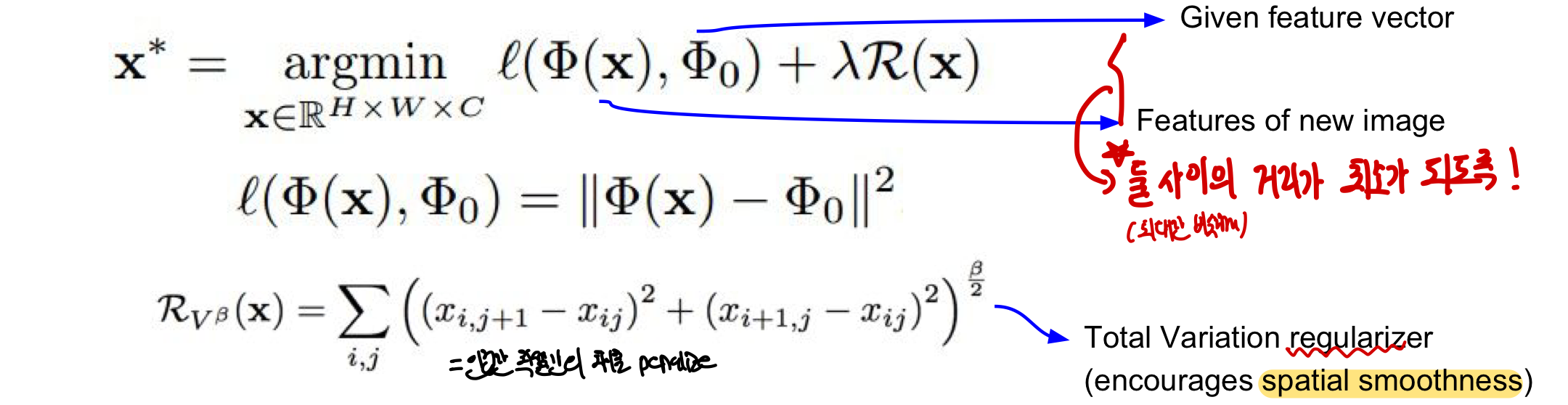
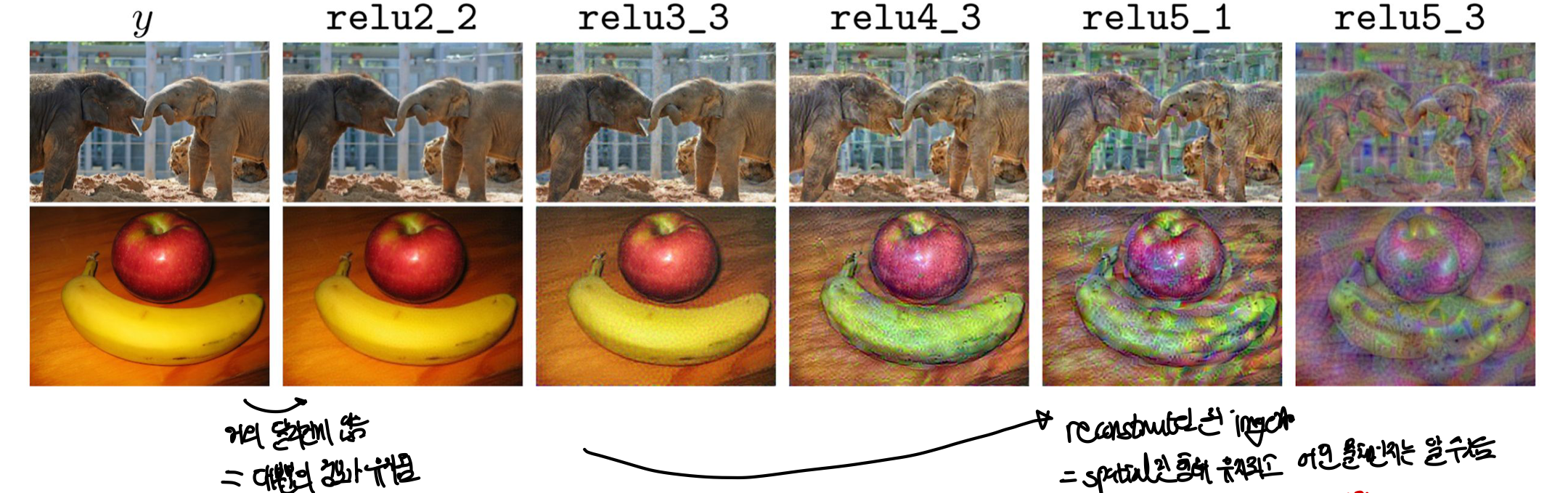
- 얕은 layer을 뽑아서 feature inversion을 진행하면 실제 image와 거의 달라지는게 없고 대부분의 정보가 유지됨
- 깊은 layer을 뽑아서 볼 경우 reconstructed된 image가 spatial한 형태는 유지되고 어떤 물체인지는 알 수 있지만 low-level detail이 사라짐
- 즉, 깊은 layer의 feature map은 더 요약되어있고 중요한 정보만 가지고 있기 때문에 이 feature map과 유사하게 만든 image 역시 중요한 정보만 남긴채 detail이 떨어지게 됨
이를 통해 layer에서 어떤 식으로 image를 포착하고, 어떤 식으로 feature을 포착하는지 확인하며 이는 새로운 image를 inversion(원본이미지와 유사하게)하면서 시각화한다
Texture Synthesis
computer graphic에서 유명한 문제로 특정한 질감(texture)의 image를 받았을 때 똑같은 질감(texture)의 더 큰 image를 생성해낼 수 있을까!
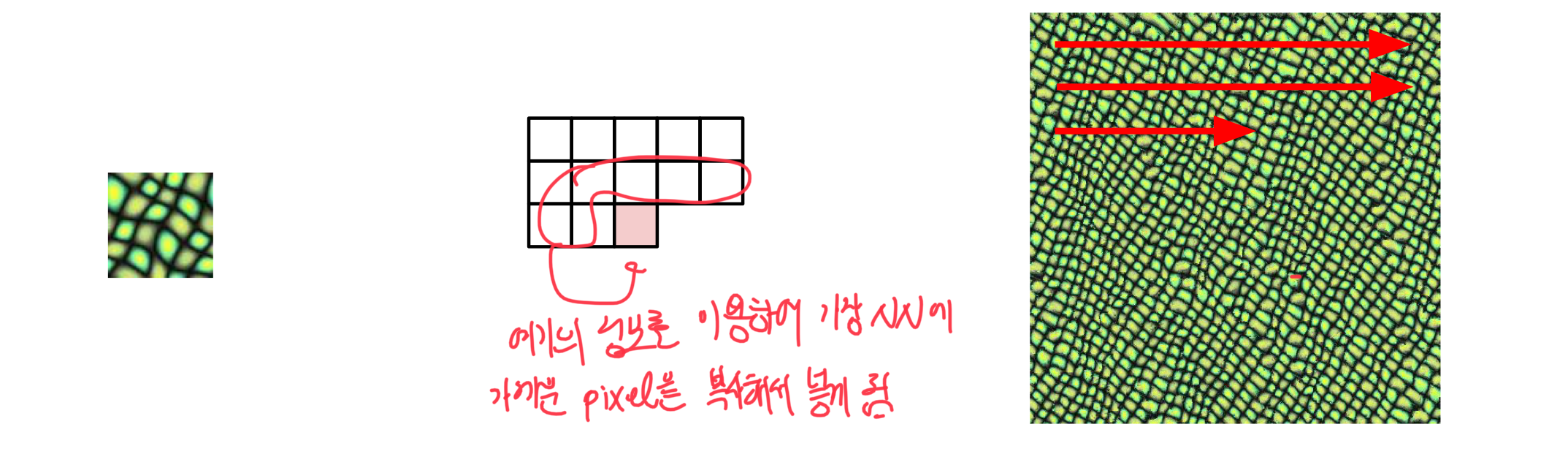
Nearest Neighbor
픽셀이 line을 훑어가며 이미 생성된 주변의 pixel들을 계산하여 그 자리에 들어갈 NN pixel을 복사하는 방식!
단순한 pattern들은 표현을 잘하지만 더 복잡한 pattern들은 잘 작동하지 않음(단순히 복사만으로 불가능 ex: 글자)
Gram Matrix (Neural Texture Synthesis)
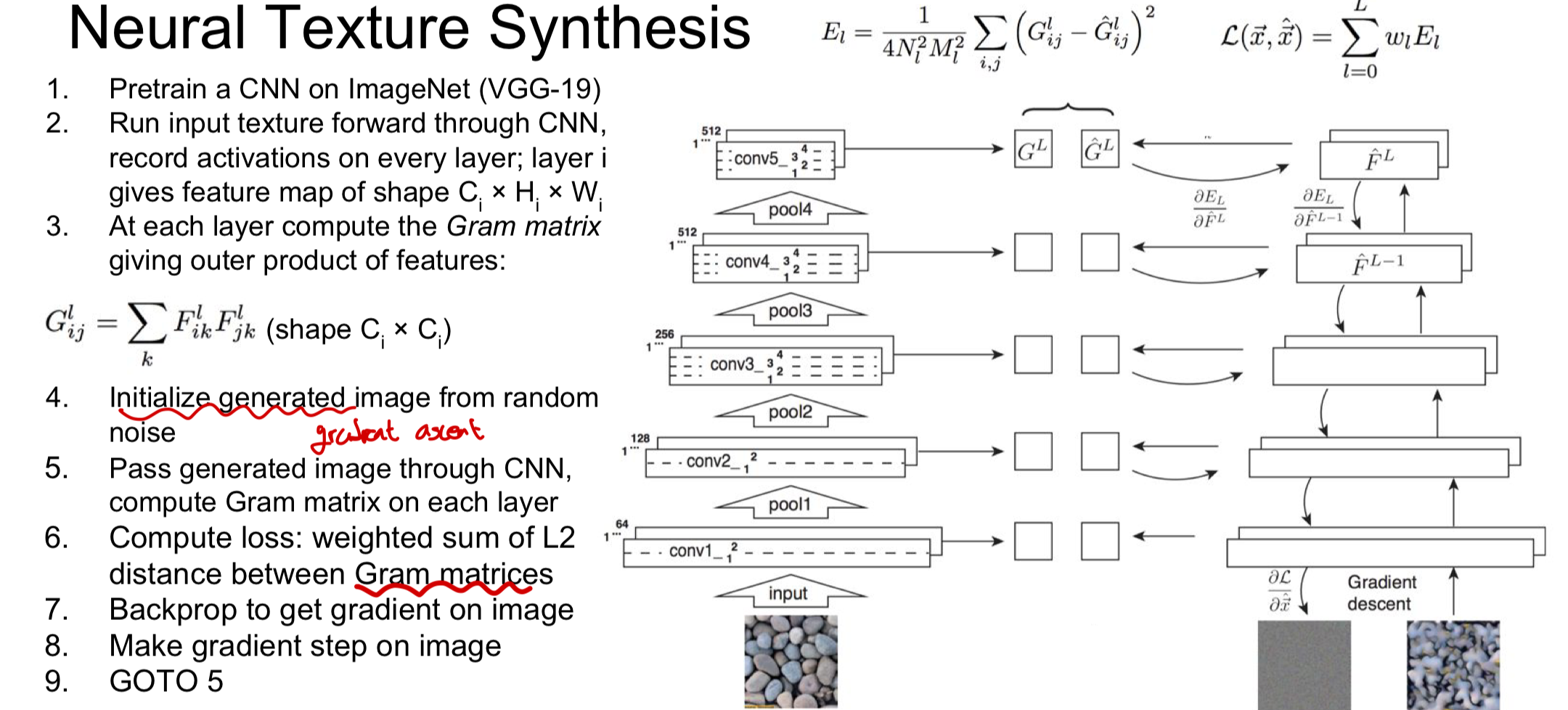
gradient ascent를 이용해서 feature map과의 비교를 통해 수정이 됨!
동작방식
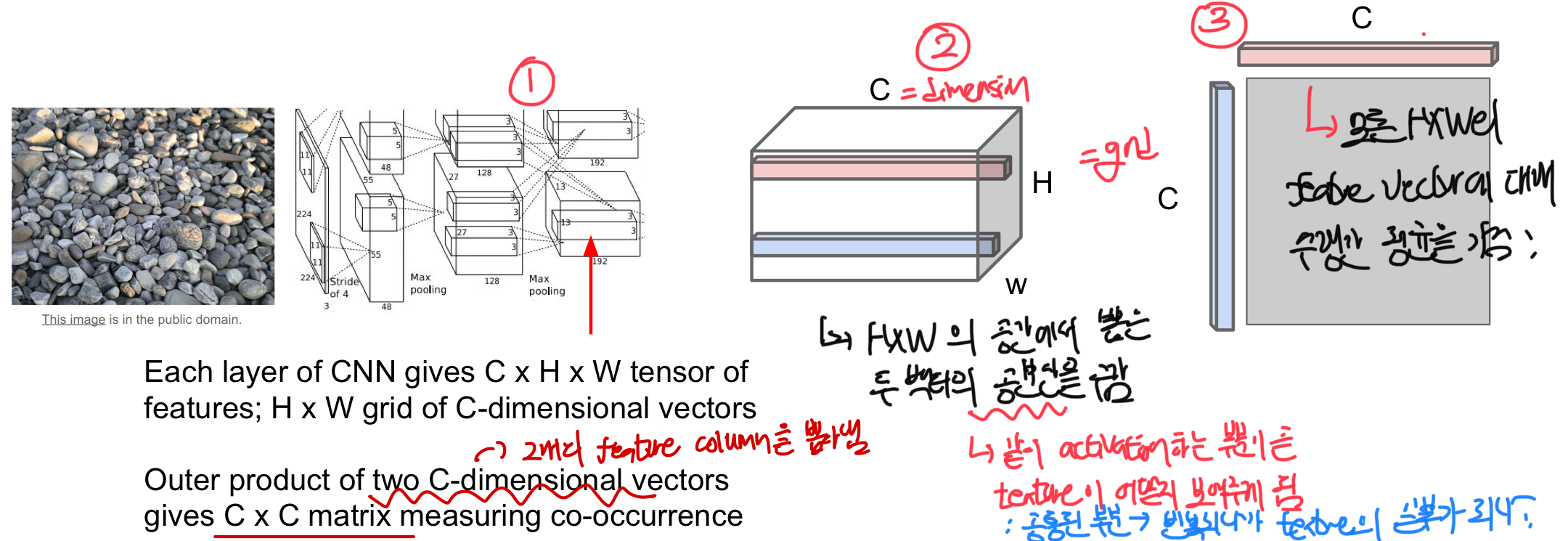
1. input data를 CNN에 넣은 후 몇몇 layer에서 feature map을 가져옴
2. 서로 다른 2개의 feature vector을 외적하여 새로운 matrix를 만듦
- 각 grid에서의 pixel의 C-dim vector들을 뽑아 모두 외적을 진행
- 두 vector의 외적은 다른 공간에서 2개의 feature vector가 같이 activate하는 부분이 어디인지를 알려줌!(=co-occurence: 공분산과 비슷한 역할)
- 같이 activation하는 부분은 공통적으로 반복되는 곳이기 때문에 texture의 일부가 될 가능성이 높은건가?
3. 이 과정을 HXW(grid의 크기)에 대해 수행하여 평균을 내면 CXC 크기의 gram matrix가 생성!
- average한 결과이기 떄문에 spatial information이 없어짐
- 이 gram matrix를 통해 input image의 질감(texture)을 알 수 있음
 computionally efficient: 계산적으로 값이 비싼 covariance를 사용하지 않고 feature을 reshape가능
- 공분산: C X H X W, gram matrix: CX(HW)
실제 image 생성 과정
computionally efficient: 계산적으로 값이 비싼 covariance를 사용하지 않고 feature을 reshape가능
- 공분산: C X H X W, gram matrix: CX(HW)
실제 image 생성 과정
 결과적으로 lower level layer의 feature을 이용하면 제대로 synthesized된 사진을 얻기 힘들지만 더 깊은 layer의 feature일 경우 input texture의 더 넓은 범위의 feature들을 담아 실제 input과 pixel은 다르지만 같은 분류의 사진(texture)로 판단하게 됨!
결과적으로 lower level layer의 feature을 이용하면 제대로 synthesized된 사진을 얻기 힘들지만 더 깊은 layer의 feature일 경우 input texture의 더 넓은 범위의 feature들을 담아 실제 input과 pixel은 다르지만 같은 분류의 사진(texture)로 판단하게 됨!

Neural Style Transfer
예술 작품에 위와 같은 방식을 적용하려는 시도가 등장
gram matrix(질감에 대한 정보를 얻어 질감을 바꿀 수 있음) + feature inversion(그림의 주요형태만 남김)
style image(texture와 style에 영향을 미침) + content image(output의 전체적인 형태) = style transfer
 style image와 content image의 feature reconstruction loss를 최소화하여 여러번의 반복을 통해 최적의 이미지를 생성하게 됨!
- 2개의 loss를 합친 joint loss function의 가중치를 조절하여 어느 부분에 더 집중할지 결정 가능
- style image와 content image를 우리가 넣어줬기 떄문에 어떤 결과가 나올지 어느정도 예상가능
- Deep Dream 같은 경우는 결과가 어떻게 나올지 모름(intermediate layer의 feature map이 어떤 object들을 포함하는지 모르기 떄문에 예상하기 힘듦)
style image와 content image의 feature reconstruction loss를 최소화하여 여러번의 반복을 통해 최적의 이미지를 생성하게 됨!
- 2개의 loss를 합친 joint loss function의 가중치를 조절하여 어느 부분에 더 집중할지 결정 가능
- style image와 content image를 우리가 넣어줬기 떄문에 어떤 결과가 나올지 어느정도 예상가능
- Deep Dream 같은 경우는 결과가 어떻게 나올지 모름(intermediate layer의 feature map이 어떤 object들을 포함하는지 모르기 떄문에 예상하기 힘듦)
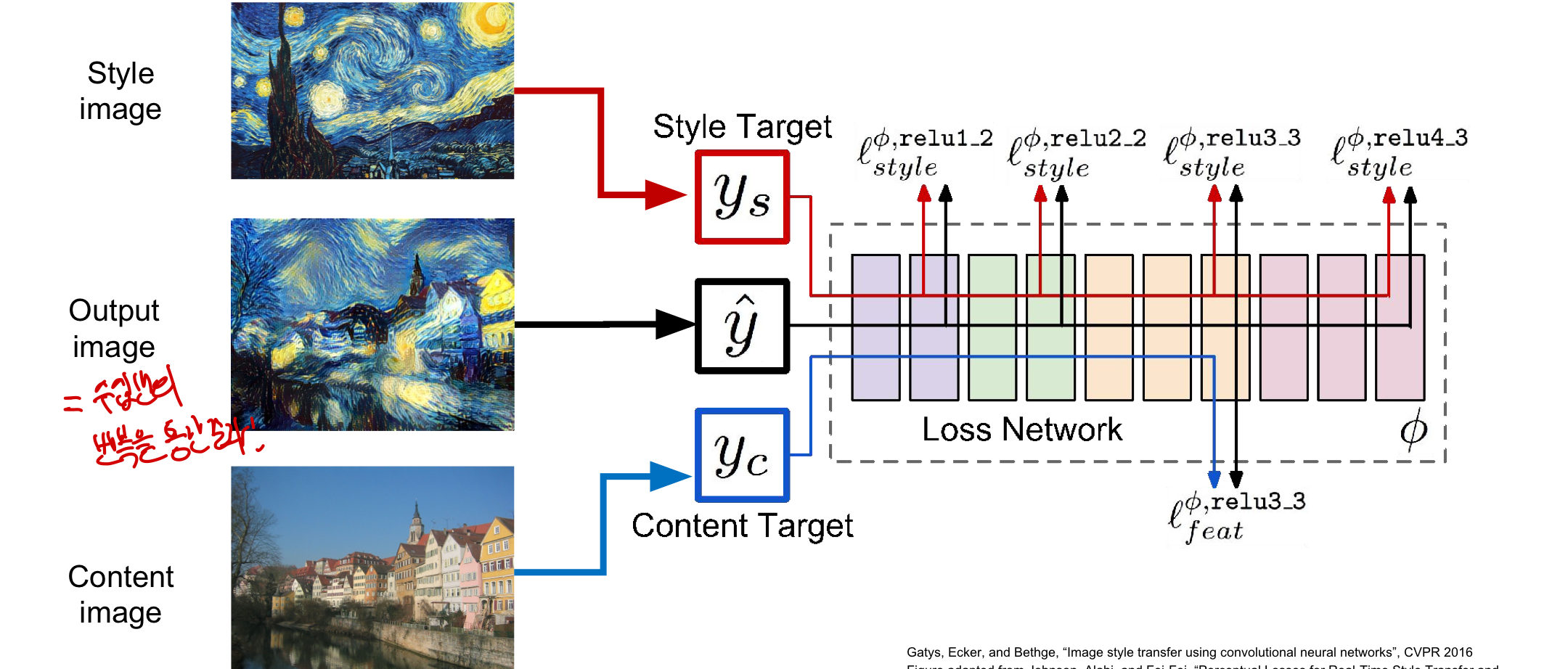 문제점: 많은 backward와 forward과정이 반복되어야하여 느림!(특히 고해상도 이미지, 몇분이 걸리기도 함!)
해결책: style transfer의 수행을 위한 또 다른 network를 학습시키면 됨!
문제점: 많은 backward와 forward과정이 반복되어야하여 느림!(특히 고해상도 이미지, 몇분이 걸리기도 함!)
해결책: style transfer의 수행을 위한 또 다른 network를 학습시키면 됨!
Fast Style Transfer
style image를 고정시키는 후 content image만 입력을 받아 결과를 출력할 수 있는 network를 학습시키는 방법!
동작방식: 즉, content image를 여러개 적용하여 training을 시키고 몇시간의 training후에 완료 될 경우 한번의 style image를 적용하여 바로 output을 만들 수 있게 만드는 것 같음!
1. 각각의 style에 따라 feedforward network를 train
2. 기존에 이미 train된 CNN을 이용하여 이전 모델과 같이 loss를 구함
3. training이 끝난 후 style하게 만들어줄 image가 single forward pass를 통해 사용됨
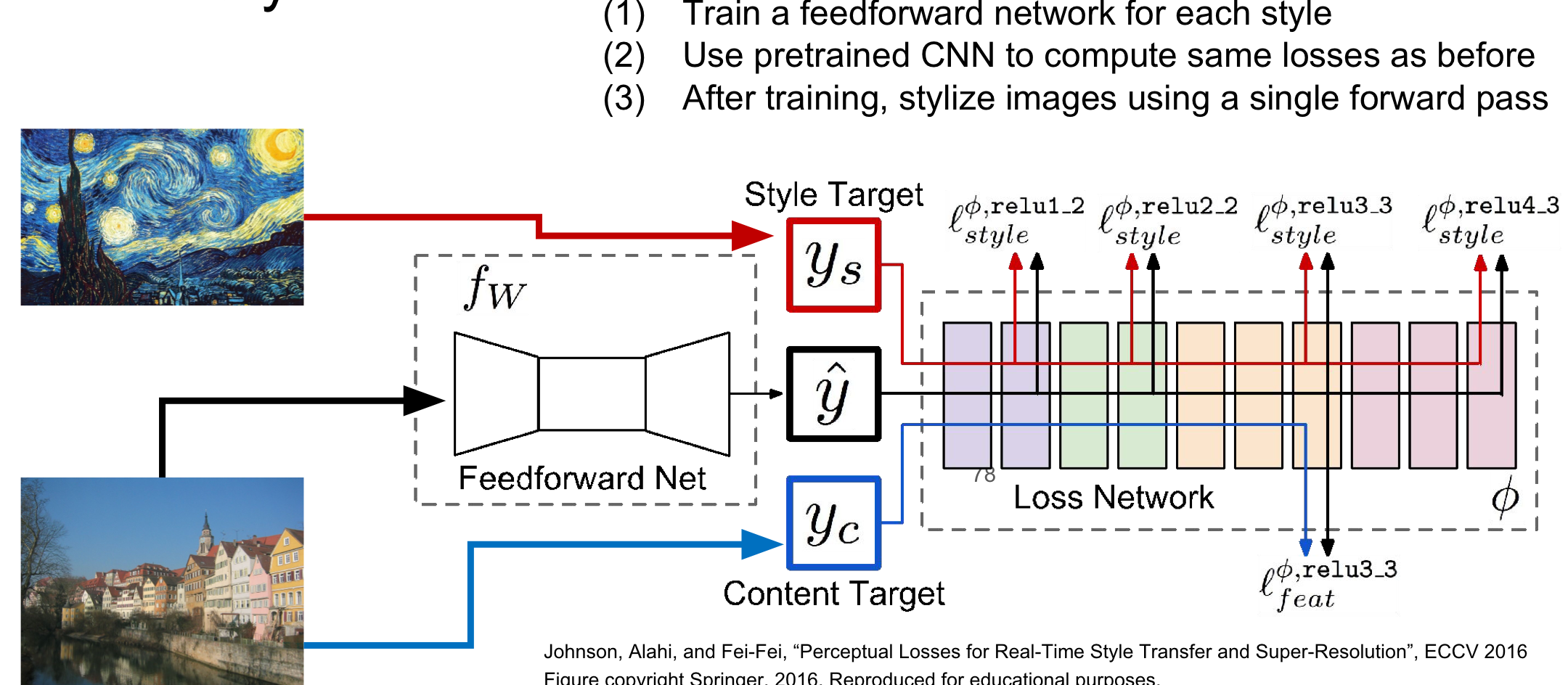 training시 시간이 오래 걸리지만(몇시간 정도) training 후에는 network에 image를 넣으면 곧바로 style(texture)가 바뀐 결과가 나옴
- semantic segmentation과 매우 유사(출력이 RGB인 것이 다름)
문제점: 하나의 network가 하나의 style(texture)만을 표현 가능(style image를 고정시켰기 때문에!)
- 근데 구글에서 하나의 network를 학습시켜서 다양한 style(texture)을 만들 수 있는 방법을 제안함
- 심지어 실시간으로 가능
training시 시간이 오래 걸리지만(몇시간 정도) training 후에는 network에 image를 넣으면 곧바로 style(texture)가 바뀐 결과가 나옴
- semantic segmentation과 매우 유사(출력이 RGB인 것이 다름)
문제점: 하나의 network가 하나의 style(texture)만을 표현 가능(style image를 고정시켰기 때문에!)
- 근데 구글에서 하나의 network를 학습시켜서 다양한 style(texture)을 만들 수 있는 방법을 제안함
- 심지어 실시간으로 가능