{kind=link}
이 논문은 전체적으로 QT 문제에 관한 연구 동향에 대해서 포괄적으로 설명을 하고 앞으로 유의해야할 점에 대해서 알아보고 있다. 특히 QT를 4가지로 나눴는데 일단 이 중에 Agorithmic trading과 portofolio management를 중점적으로 확인해봐야할 듯하다!
1. Introduction
Quantitative Learning(QT)이란? 투자를 할 때 수학과 통계학은 이용한 모델을 사용하여 자동적으로 투자 기회를 찾는 시장 전략이다! 참고로 현재 QT는 미국 시장의 70%가 사용할 정도로 매우 시장이 큰 상태이다! 생각보다 이미 엄청나게 많이 사용하고 있었네.. 이때 QT는 두가지로 나뉠 수 있는데, 경제학자들이 경제시장을 설명하기 위한 이론과 모델과 컴퓨터 과학작들이 ML을 이용하여 경제적 데이터를 분석하는 방법이 이다. ⇒ 최근에 딥러닝과 함께 증가! 이 중에서도 특히 강화학습(RL)을 이용하여 QT 문제를 해석하는 것이 가장 최신의 뛰어난 성능을 나타낸다.
1-1. 왜 하필 QT에 RL을 사용할까?
Summary
기존 (휴리스틱, 딥러닝) 성능 안좋음. RL은 4가지 장점이 존재하여 QT 문제에 적합함
기존의 경험적으로 얻은 금융적 지식을 이용해 금융시장의 근간에 있는 규칙을 찾는 것은 일반화 능력이 떨어지는 문제가 존재했다. 딥러닝 모델 역시 주식 예측을 할 수 없었다.(input과 output사이에 연관관계를 알기 위해 너무 오랜시간이 필요할거임 ) 또한 이렇게 예측하는 것과 실제 트레이딩 하는 것에는 차이가 존재함 LSTM으로 주가 예측 직접해봤을 때 안된다는 것을 알 수 있었음
반면에 RL은 다음 4가지 특징이 존재하여 QT에 적합하다
- end-to-end agent를 학습 가능하다 (시장 정보 → 트레이딩 action 가능)
- 엄청나게 어려운 일(예측)에 뛰어남
- 실제 환경과 비슷한 환경을 RL 내에 구축할 수 있음 (수수료, slippage)
- 어떤 시장의 환경이든지 일반화할 잠재력이 있음
1-2. 이 논문과 기존 연구들과의 차이점!
기존 연구들을 분류해서 정리를 했으며 RL 알고리즘 관점과 이것을 실제로 적용한 논문을 합쳐 QT에 적용된 RL 방법들을 요약하는 것이 목표이다! 최근에 많은 논문들이 나왔으며 100개 이상의 믿을만한 연구들을 사용했다.
⭐️ 1-3. 그럼 어떻게 연구들을 모았냐?
- [!]
ICAIF(최근에 생긴 RL-Finace관련 학회 ,JP모건)와 같은 학회에 있는 논문들을 읽어볼 필요가 있는 듯. 그리고한번쯤 가보고 싶다!
- 논문 사이트에서 관련 논문 검색
- 주요 컨퍼런스에 발행한 연구들 이용(NeurIPS,ICMI: 국제머신러닝학회 ,IJCAL: 인공지능국제회의, ICAIF)=
각각 무슨학회이고 한번씩 읽어보려고 하는 것도 좋을 듯 - quantative finance, algorithmic trading같은 키워드로 주로 확인
1-4. 이 논문의 핵심과 의의
- QT에 적용된 RL관련된 논문들을 정리하고, 다른 관점에서 분류하였다.
- RL 기법의 장점과 단점을 다룸
- 앞으로 나아갈 방향을 제시하고 이때 마주칠 수 있는 문제점을 다룸
2. QT 배경지식
-
Renaissance, Two Sigma, Citadel, D.E.Shaw- 이런 회사는 어떻게 수익을 내는지, 혹시라도 입사할 수 있을지?
이 논문에서는 QT의 종류를 4가지로 분류했는데, 나는 이중에 algorithmic trading(AT)와 portofio management(PM)에 관련해서 집중적으로 확인할 것이다. 이때 AT와 PM은 나머지 OE와 MM보다는 큰 규모에서 진행이 되며, 하나의 주식을 다룰 떄는 AT, 2개 이상의 주식을 다룰 떄는 PM을 이용한다.
금융에 대한 전반적인 지식(금융중심지, 투자 종류, 이해당사자을 설명한다. 이때 이미 quantitative trading을 이용해서 상당한 수익을 얻은 회사들이 있다고 한다. (Renaissance, Two Sigma, Citadel, D.E.Shaw - 이런 회사는 어떻게 수익을 내는지, 혹시라도 입사할 수 있을지?) 또한 경제적 용어에 대한 간단한 설명을 한다. (보유기간, OHLC, 수수료, 유동성: 돈으로 얼마나 쉽게 바꿀 수 있는지 )
⭐️Algorithmic Trading (AT) - Baseline 후보
- swing trading,day trading,scalping trading(드되면 제일 좋을듯)이 현실적으로 가능한 것들일듯 (가장 현실적인 건 day trading, 되면 scalping을 하고 싶음)
- [!] baseline 방법들이 될만한 전략에 대해 말하고 있음! (BAH,momentum,bollinger)
AT에서는 net value(주식의 가치 당 자금의 비율)과 position이 state가 되며 기간에 따라 5가지로 트레이딩 종류가 나뉜다. 이때 position trading(장기투자)은 직접 구현해본 결과 잘 들어맞지 않았고 Day trading(일 단위)과 scalping trading(몇분 단위: 연구가 적고, 현실적으로 어려움이 있긴할듯)을 목표로 트레이딩 모델을 만들면 좋을 것 같다는 생각이 됐다
기존의 전통적인 AT 방법에는 다음과 같은 전략이 존재하며 이것들은 사람들에게 잘 알려진 전략이기 때문에 이들을 baseline으로 잡아 모델이 얼마나 나은 성능을 보여줬는지 확인을 할 때 중요하게 사용될 수 있다.
- Buy and Hold(BAH)
- Momentum stratgy(기존의 추세가 계속 지속)
- Bollinger bands(기존의 추세와 반대로)
전통적인 방식에 한계가 존재하며 비교하는 정도로 알맞음
⭐️⭐️ 평가 지표 - Reward 후보
- [!] 여기서 나오는 metric을 통해 모델의 성능을 확인하고
reward를 무엇으로 할지 생각해볼 수 있음 - [!] 수익성 뿐 아니라 위험도도 중요하기 때문에 여러 논문에서, 그리고 이 논문에서
Risk-adjusted metrics를 사용하는 것이 일반적인듯 함
수익성과 위험 조정된 평가 지표에 대해서 알아보고자 한다. 여기서 다루는 평가 지표를 통해 모델의 성능을 확인하면 될 듯하다!
Profit Metrics
- Profit rate(PR): net value가 얼마나 변했는지 %로 나타낸 지표
- Win rate(WR): 트레이딩을 한 날 중에 수익을 창출한 날의 비율을 이용하는 지표
Risk Metrics
- Volatility(VOL): return의 분산을 의미하며, 수익률의 불확실성을 측정할 때 널리 쓰임
- Maximum drawdown(MDD): 가장 최악의 경우를 보여주며, 가장 큰 규모의 하락을 측정하는 지표
- Downside deviation(DD): 손실(return중 손실만)의 분산을 측정하는 지표이다.
- Grain-loss ratio(GLR): 손실의 비중과 수익의 비중을 나타내는 지표로, (수익의 비중)/(손실의 비중) 이므로 값이 클 수록 좋다.
Risk-adjusted Metrics ⇒많은 논문에서 이 방법들을 주로 사용함
- ⭐️⭐️ Sharpe ratio (SR): 편차 단위당 수익률을 의미하며 편차가 적을 수록 risk가 적다는 의미이다 ()
- Sortino ration(SoR): 위에서 업근함 downside deviation을 위험 측정 방법으로 이용하여 DD당 수익률을 의미한다()
- Calmar ratio(CR): 위에서 언급한 maximum drawdown(MDD)를 위험 측정 방법으로 사용한 방법으로 MDD당 수익률을 의미한다 ()
3. 강화학습 (모델)
주요 DRL 알고리즘
-
[!] 개인적인 생각에는 A2C와 DDPG과 금융데이터 관련 분석에 잘 맞을 것 같다.
-
DQN: DQN(2015) Human-level control through deep reinforcement learning 이 글에 제대로 정리되어있으며, off-policy learning을 하며 experience replay와의 결합을 통해 Q-learning 알고리즘을 발전시켰다. 이때 target network이 이따금씩 업데이트되게 만들어 너무 많이 변화하지 않게 만든 것이 특징인 네트워크이다
-
PPO: policy gradient를 사용한 방법으로 새로운 대체제의 objective function을 사용한다. 이 네트워크의 특징으로는 더 높은 sample 복잡도에서도 쉽게 적용이 가능하며 기존의 region policy optimzation의 장점을 모두 가지고 있다.
-
A2C: experience replay대신에 여러개의 agent를 동시에 실행시키는 알고리즘으로 agent의 데이터의 상관관계를 없애는
stationary 과정이라고 볼 수 있다. on-policy 알고리즘에 넓은 범위에서 적용가능하다 ⇒데이터의 관계를 decorrelate시키고 stationary하게 만든다는 점에서 주식 데이터에 잘 맞을 것 같다는 생각이 듦! -
SAC: off-policy, actor-critic방법으로 soft policy evalutation과 soft policy improvement 방식으로 나뉘어 번걸아가면 업데이트가 된다. 또한 연속적인 action space를 다루기 위해 policy를 Gaussian을 따르게 모델링을 할 수 있어 금융데이터에 사용이 가능하다
-
DDPG: model-free-off-policy 알고리즘으로 experience replay를 사용하며 연속적으로 정의된 action을 학습한다(DPG와 DQN을 섞음) ⇒
금융데이터와 같은 continous data에 잘맞을듯!
4. 지도학습를 이용한 QT
- 결론적으로 말하면 머신러닝을 이용한 주가예측에서 내가 직접 확인했다 싶이 지도학습을 통해 QT를 하는 것에는 한계가 있다!
- feature engineering에서
PCA를 통해 규칙을 찾아보는 것도 연습을 해보기에 좋은 방법일 듯싶다! - 내가 기존의 LSTM을 이용한 방식에다가
경제뉴스,sns등과 같이 sentiment analysis를 통해 예측하는 방식도 한번 해보면 좋을듯! - [!] 12p 4-3 Enhancing Traditional Methods with ML에 나오는 논문들,
어떤 방법을 썼는지 아이디어만 확인해보면 좋을듯
feature engineering: 미래 주가를 예측하고 설명하는데 필요한 features들을 alpha factor라고 하는데 이를 찾는 과정이다. 즉, 주식에서 의미있는 feature을 찾는 과정인데 애초에 주식이 규칙이 있다고 보기 어렵다
financial forecasting: 회규(regression)을 이용해 예측을 하고 분류(classification)을 통해 가격 추세를 예측하는 방법인데 svm, LSTM,CNN 등을 사용하여 예측해볼 수 있다. 이 자체만으로 성과를내기 어렵고 경제 뉴스,sns 등을 이용하여 예측을 진행하면 의미있는 결과를 도출할 수 있을 것으로 기대 6-2에서 다시 언급되는 내용
이외에도 ML을 이용하여 전통적인 방식을 향상시킨려는 시도가 있었는데, 모두 예측과 수익성있는 트레이딩과는 무시할 수 없을만한 차이가 존재했다
5. RL을 이용한 QT
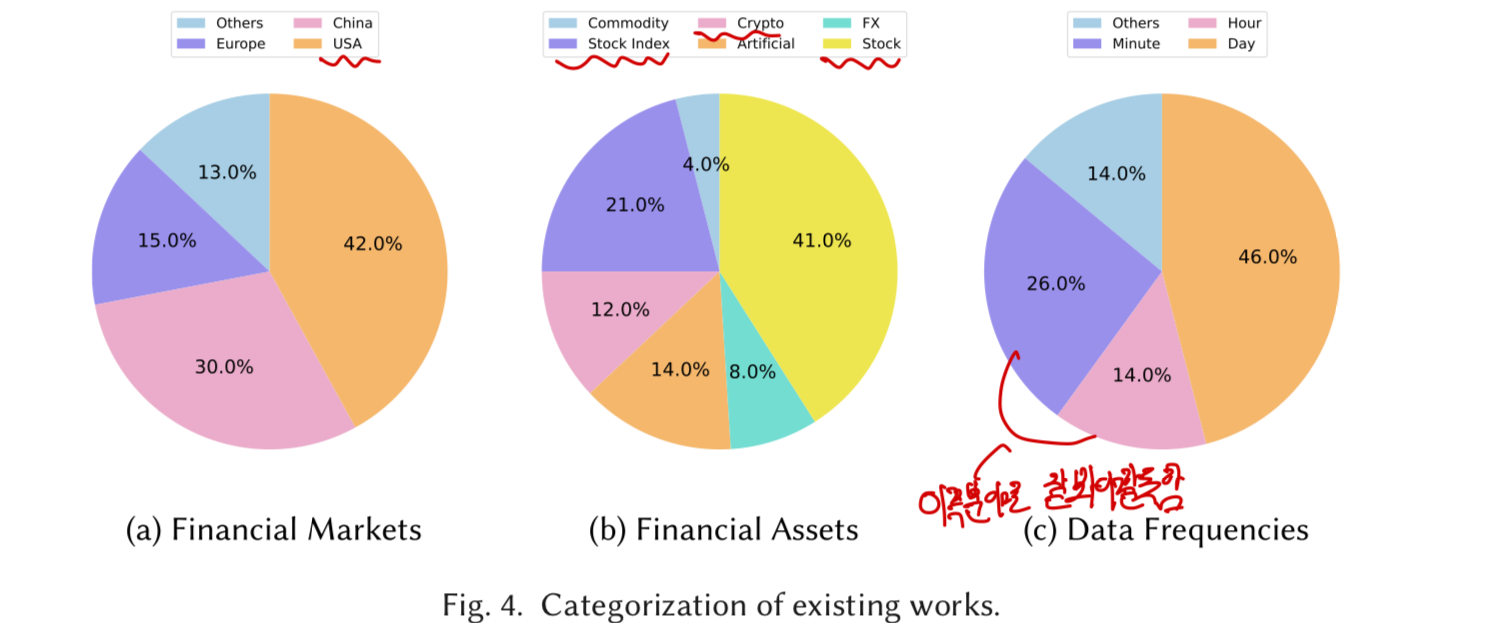
RL을 이용한 QT모델의 분포
- 가장 자주 쓰이는 RL 알고리즘: Q-learning & Recurrent RL
- ⭐️최근에 많이 쓰이는 RL 알고리즘: DQN,DDPQ,PPO (기존의 성능보다 증가)
- 자주 쓰이는 금융시장: 미국 > 중국 (초기에는 유럽)
- 가장 많이 쓰이는 금융자산 주식 > 주식 지수 (최근에 암호화폐 증가추세)
- ⭐️데이터 시간 단위 : 일간 > 분간 > 시간
RL in 트레이딩(AT)
Conclusion
결론! quantative trading에 대해서 RL이 잠재력을 가지고 있지만 RL알고리즘에 일반적인 순위에 대한 합의점이 없다!! (
no free lunch theorm)
- [!] 즉 답이 없다! 결국 내가 집중하고 중요하게 생각하는 기준을 정해 그에 맞는 모델을 만들 필요가 있음!
Policy-based 방법
- 기존 방식= RRL ➡️ 딥러닝 추가 =FDDR
- [!] LSTM과 함께
multi-objective RL(논문 마지막에 제안하는 방식!)을 이용하여 profit과 Sharpe ratio(위험)을 동시에 최적화
Moody and Wu[93]: 기존의 지도학습 방법에 대한 한계를 제시하고 RRL(recurrent RL) 모델과 Differential Sharpe Ratio 라는 새로운 평가지표를 사용하여 기존의 모델들 보다 성능을 향상시켰다. 이와 같은 알고리즘으로 S&P 500 지수와 US 달러/파운드 교환 데이터에도 사용하여 추가적인 실험을 진행한 논문이 존재한다[92,94]Dempster and Leemnas[29]: 이 RRL에 대한 확장으로 3개의 layer과 함께 adaptive RRL framework를 제안했다. 각 layer은 기술적 지표의 추가, 리스크 지표를 통한 layer 1의 trading action 평가, layer 2의 hyperparameter의 탐색의 역할을 맡았으며 유로/달러의 교환 데이터에서 기존의 baseline보다 우수한 성과를 얻었다. 이어 Vittori et al[136]은 TRVO(Trust Region Volatility Optimization)이라는 리스크 대응 알고리즘을 만들으며 서로 다른 리스크 대응 방법들에 의해 학습되어 Black&Scholes delta hedge의 성능을 뛰어 넘었다
딥러니의 발전과 함께 몇몇 DRL 방법을 이용한 트레이딩 방법이 생기기 시작했다. ⭐️FDDR[30] 방법은 기존의 RRL 방법을 deep neural network을 추가해 향상시킨것으로 시장의 특징을 학습할 뿐 아니라 불확실성을 줄일 수 있었다. 그 결과 선물과 주식지수에서 높은 성능을 보였다. 또한 이익과 손실의 균형을 맞추기 위해 ⭐️⭐️LSTM과 함께 multi-objective RL 방법[118]을 사용하는 추가 연구가 있었고 profit과 Shapre Ratio을 동시에 최적화 시켜 중국주식시장에서 더 나은 성능을 보였다
Value-based 방법
- multi-agent Q-learning(agent끼리 서로 공유)
- [!] heuristic trading 방법을 Q-learning target에 넣음
deep neural network를 사용하지 않아 성능은 낮겠지만, off-policy를 공부하는 입장에서 사람이 policy를 지정했을 때 어떻게 학습하는지, 기존의 유명한 heuristic 트레이딩 방법에는뭐가 있는지 볼 필요가 있는듯 - [!] DQN 트레이딩 많이 높은 성능을 보임!
크게 Q-learning을 사용한 방법과 이에 대한 향상된 방법인 DQN을 사용하는 방법으로 나뉜다. DQN(2015) Human-level control through deep reinforcement learning
QSR[46]은 Q-learning을 이용해 profit과 위험조정 profit(리스크)를 각각 최적화 후, 두 개를 합쳐 달러/독일 화폐간의 교환데이터에서 더 나은 성능을 보였다.⭐️ Lee and Jangmin[74]는 multi-agent Q-learning을 이용하여 4개의 agent(트레이딩 신호 만들고 매수,매도 진행)들이 학습 에피소드들을 공유하여 policy을 서로 학습하게 되어 profit과 리스크 관리에서 더 높은 성능을얻음(한국 주식시장 사용, baseline: 지도학습) 이외에도[62]-한국?에서 실제 트레이더가 사용하는 heuristic 방법들을 Q-learning에 적용(기존에 heuristic 방법으로 ML trading을 했을 때 좋지 않았다고 했는데, 여기서는 어떤 결과를 가져왔는지 궁금함 + Q-learning이니까 target을 내 맘대로 넣을 수 있는데 이 과정에 대해서 공부할 필요가 있다고 생각해서 한번 가볍게 보면 좋을듯)하거나[27]SARSA 기반 RL을 이용하는 방법도 있다.
DQN은 trading frequency(low/high)와 시장 혼란등을 고려하여 트레이딩 시스템을 향상시키는데 사용이 된다. 이때 trading frequency는 1) Q-value와 연관된 heuristic 함수, 2)action dependent NN, 3)action-independent NN에 의해 결정되며 (뭔 뜻인지 잘 모르겠음) 시장에 따른 agent의 확신도와 weight를 미리 계산함으로써 모델이 완성된다
⭐️DeepScalper[125]는 branch deuling Q-network을 이용하여intraday trading을 했다. 이때 encoder-decoder 구조를 통해 미시적, 거시적 시장의 정보를 통합했으며 추후의 얻는 이익도 추후에 reward function에 넣어 장기적으로 학습이 가능하게 만들었다.(내가 읽은 한국 논문도 이랬음 => 추가적인 보상을 넣는 것이 나름 일반적. 근데 왜 추후 reward가 생길까..? 나중에 판걸 얘기하는건가) 부수적으로 미래의 변동성까지 예측할 수 있게 만들어 중국 시장에서 baseline보다 상당히 높은 성능을 보였다.Riva et al[106]은 FX trading에 value-based RL알고리즘으로 agent를 학습시켰으며 효과적인 policy를 얻기 위해 frequency(거래량)을 조절하는 것이 중요하다는 결과를 얻음
나머지
-
[!]
[62]와 iRDPG[87]모두 전문 트레이더의 방식을 각각 target과 behavior로 삼아 학습하는데, 그냥 heuristic 방식으로 모델을 구성하는 것이 아닌 heuristic 방식을 network가 학습하는데에 적용함으로써 성능이 좋아지는 것이라고 볼 수 있을 듯! -
iRDPG[87]은DPG기반 framework로 금융데이터가 애초에 noisy한 특성을 갖고 있기 떄문에POMDP(Paritially Observable Markov Decison Process)로써 알고리즘 트레이딩을 구성한다. 이때 iRDPG가 현재의 금육시장을 학습하기 위해GRU layer을 이용하며, iRDPG의 높은 성능을 달성하기 위해 전문가의 trading action을 behavior에 복제하는 방법을 사용하여 중국 주식 지수선물 시장에 좋은 성능을 보였다 -
Zhang et al[161]은 50가지 liquid 선물 계약에 대해 DNQ,PG,A2C의 성능을 비교했고Yuan et al[155]은 3가지 주식에 대해 PPO,DQN,SAC의 성능을 비교한 결과 DQN이 가장 높은 성능을 보였다고 한다
⭐️ 6. 한계점과 향후 발전 방향
6-1. 새로운 RL기술을 통한 발전가능성
- [!] 충분한 데이터 확보, reward의 다양성(MultiObjective), 새로운 학습 방식(graph learning), 일반화 상승(Meta, transfer learning), 복잡성 하락(Hierarchical)와 같은 방식을 고려해보면 좋음!
- graph learning이 뭔지 좀 더 알아보자!!
이전의 논문을 읽으면서 중요하다고 생각되던 내용들이 정리되어 있다. 생각들도 정리되는 것 같아서 좋은 부분인듯!
- 데이터의 확보가 중요 ex) 예를 들어 극단적 금융위기들도 학습을 해야함
multi-objective RL를 이용하여 이익의 극대화와 손실의 최소화⇒ 이익과 손실 사이의 trade-off를 계산(reward나 policy를 달리 하면서 학습을 진행)
Multi-objective RL
MORL로 불리며 여러가지 목표를 동시에 최적화하는 문제를 다룬다. 이때 여러 개의 보상함수를 가질 수 있으며, 1)여러 목표를 균형있게 달성할 수 있는 policy를 학습한 후 2) 스칼라화 기법을 이용해 여러 목표를 하나의 목표로 통합하고 3) 이때 목표간의 최적의 균형을 찾기 위해 파레토 최적화을 사용한다.
즉, 이런 방시을 통해 수익률을 최대화하고 리스크를 최소화하는데 사용이 가능하다 (주로
포토폴리리오 PM에서 사용)
graph learning이용! ⇒ 이미 지도학습에서 graph learning과 주식 사이의 유망한 관계를 확인할 수 있었음! 그럼 RL에서도 잘 적용되지 않을까?graph_learning 열두 발자국
Graph learning?
데이터간의 관계를 그래프 구조로 표현하고 이 그래프에서 정보를 학습하는 기법으로 GNN(Graph Neural Network)를 사용하여 노드간의 관계를 학습 가능
이때 노드를 주식으로, 엣지를 주신과의 관계로 정의 후 그래프를 구성한 뒤 그래프 신경망(GNN)에 적용하여 상호작용을 모델링하고 노드 임베딩(노드를 고차원 백터로 표현)을 통해 미래 가격 변동 예측/ 주식 분류등이 가능할 수 있다.
4.Meta-RL, transfer learning을 통해 일반화 성능을 높일 수 있음
Meta-RL & Transfer Learning?
Meta RL: agent가 다양한 환경에서 빠르게 학습하고 적응할 수 있도록 하는 기법으로 “학습하는 방법을 학습”한다고 볼 수 있다. 이를 사용하여 이전에 학습한 경험을 활용해 새로운 시장 조건에 빠르게 적응할 수 있음
Transfer Learning: 한 분야에서 학습한 지식을 다른 분야에 적용하는 방법으로 사전 학습된 모델을 사용하여 학습시간을 단축하고 성능을 향상시킴. 금융시장의
데이터 수집이 어렵기 떄문에이를 이요해 적은 데이터로 효율적으로 모델 학습 가능 CS231n 7-2. Evaluation & Regularizationtransfer_learning
Hieracrhical RL방법을 이용하여 모델의 작동방식을 다른 사람들이 이해할 수 있도록 보여줘야함 ⇒ 초공간[[초공간]]에서도 과학이라는 것이 자신이 맞다고 다른 대중들을 설득하지 못하고 고집을 부르는 것을 주류가 되지 못한다고 했다. 결국 다수의 사람에 인정을 받아만 비로소 의미있고 주요한 과학이 되므로, 내가만든 모델도 후에 사람들을 설득하고 판매를 하려면 설득하기 위해서 꼭 필요한 과정인듯!
Hierarchical RL(HRL)?
강화학습의 한 분야로 학습과정을 계층적으로 나누어 복잡한 문제를 해결한다. 이때 고수준의 추상적인 high-level policy와 여기서 정한 구체적인 행동을 하는 low-level policy로 학습의 복잡성을 줄일 수 있음
- 현재 실제 금융시장을 통해 직접적으로 학습하는 것은 비효율적! 즉, 실시간 트레이딩은 안좋다 ⇒
당연한듯, 내가 모델을 만들면 특정 주기마다 다시 학습을 시켜, 실제 금융시장을 최대한 맞춰나가려고 노력해야할듯!
6-2. 대체 가능한 데이터와 새로운 QT 설정
- [!] 금융시장에서 투자자의 심리를 이용할만한 데이터를 사용하면 성능을 높일 수 있지만, 실제 내가 만들 모델에 적용가능할지는 모르겠고 어차피
단기투자 모델 만들 듯 하기 때문에 장기투자할 떄 고려해보면 좋을듯하다 - [!] 내가 만들고 싶은게 단기매매 트레이딩이었는데 이게 아직 제대로 연구가 안됐다니.. ⇒
일일 종가를 이용한 트레이딩에 초점을 두거나 그래도 하루 내에 주가와 관련해 연구한 논문을 이용해서 만들어보자!
금융시장에서 기존의 데이터들 말고도 다른 데이터들이 예측에 사용될 수 있다. 사용 가능한 예로는 경제 뉴스 ,SNS, 투자 행동들이 있으며 이 지표를 합쳐 RL의 성능을 높일 수 있다 ⇒ 주식은 무규칙적이며 사람들의 심리가 반영된 결과임! 이런 지표를 사용하는 것이 좋기는 하겠지만 현실적으로 주가예측 모델을 만들 때 적용 가능할지는 미지수 + 이건 장기투자에서 고려해볼만 할듯
또한 아직 QT에 관련한 모델에서 high frequency 트레이딩과 intraday trading에 대해서는 아직 연구된 바가 적기 떄문에 이 분야에 대해서 연구가 필요하다
⭐️ 6-3. Auto-ML을 이용해 성능 향상시키기
- [!] Auto-ML도 사용해봐야할 듯!
Google Cloud AutoML, H20.ai,TPOT등의 사이트가 존재하며 예측 모델을 구축하는데 큰 도움이 됨
금융 데이터의 noise와 RL 방법의 어려움 때문에 RL을 이용한 QT 모델은 RL component등에 의해 매우 신중히 설계 되어야한다. (Reward function, hyperparmeter tuning) 이때 사용할 수 있는 것이 Auto-ML로 feature engineering, hyperparameter 탐색, neural network 탐색 등을 자동적으로 할 수 있다. 이를 통해 더 RL을 잘 모르더라도 쉽게 사용가능하게 만들 수 있다.
6-4. ⭐️더 현실적인 simulation
- [!] 다른 트레이더의 action을 simulation에 넣는 방법도 생각해볼 필요가 있음! (
논문 간단하게 찾아보고 성능이 좋으면 넣는걸 고려해보자!) - 수수료, execution cost, slip page는 이미 들어가있으므로 simulation 구축에 필수적
RL을 이용해 트레이딩 모델의 성공 여부는 얼마나 실제 환경과 유사하게 simulation을 만들고 실행할 수 있느냐에 달려있다. 특히 수수료, execution cost, slip page와 같이 현재 고려한 것들로는 충분하지 않다.
특히 다른 트레이더의 action에 대한 영향이 고려되어 있지 않다. 따라서 기존의 시장 데이터만을 가지고 학습하는 것은 충분하지 않으며 이를 다룬 논문들을 간단하게 살펴보면서 현실적인 simulation을 구축해보자
⭐️ ⭐️6-5. 이 분야에서 통합되어야하는 부분과 엄밀한 검정의 필요성
- [!] financial-RL 분야에 일반적인 ranking에 대한 합의가 없음 → 가장 좋은 모델이 뭔지 알 수가 없음 ⇒
내가 트레이딩 모델을 만들고 싶어도 어떤 모델이 뭐를 참고할지 몰랐던 이유가 이거였구만! + 내가 중요시하는 부분을 정하고 이를 통해 만드는게 중요할듯! - [!] 결국 성능이 뭐가 좋은지 모르는데, 이와 관련하여 visual detection과 같이
trading 대회같은건 없는지 알아보자! - [!] 모델의 성능을 얘기할 떄 수익성 뿐만 아니라 위험도등도 포함되어야함!!!
- [!] backtraking을 통한 성능 확인 방법 좋지 않음 ⇒ rolling basis/ 믿을만한 baseline을 만들어 사람들을 설득시키기 초공간
결론에서 나오다 싶이 사람들을 설득시킬 수 있는 이론이 주류의 과학으로 도달할 수 있는 것처럼 사람들이 믿고 설득할만한 baseline이 존재해야만, 이를 뛰어넘은 나의 모델이 있을 떄 사람들로 하여금 설득이 가능해짐 - 그래도 여건상 bactrackng을 통해 성능을 검사해봐야하긴 할듯
현재 SOTA(State of the art) baseline을 확인해보더라도 baseline과 dataset이 매우 임의적이고 그에 따라 QT 문제에 대해 일반적인 ranking에 대한 합의가 없는게 문제이다. (image detection에서 처럼 특정 dataset에서의 정확도 같은 것이 중심이 되지 못함. 매년 주최되는 대회에 필요성, 이런게 있나? 그리고 이떄문에 내가 트레이딩 모델 만들고 싶어도 뭐가 가장 좋은지 몰랐던 이유였음) 이거에 대한 합의가 필요하며, 현재 대부분의 모델들이 수익성만을 강조하는데 위험도나 일반화 정도등의 지표들도 포함하여 모델의 성능을 확인해야함
또한 bactracking을 통한 평가가 효과가 없을 수도 있다! 기존의 데이터에 의해 overfitting될 가능성이 높고 실세계 적용에 어려움을 겪을 수 있기 때문이다. 그래서 모델의 성능을 확인하는 방법을 바꿔야한다. 그 중 하나의 방식이 데이터를 나누어 rolling basis 방식으로 일정 기간마다 train-validation-test를 나눈어 진행하는 방법이다. (기존 한국 논문에서 이 방식을 사용하는 경우가 있었는데 그때는 주가 데이터의 scale의 차이를 줄이기 위해서 였음!) 또한 hyperparameter tuning을 baseline과 자신의 모델 둘 다 진행시켜 사람들이 믿을만한데 비교할만한 baseline이 존재하여 사람들로 하여금 설득을 할 수 있게 만들어야함
7. 결론
이 논문은 기존의 연구들을 분류하였고 중요한 연구 프로토타입들을 강종하여 설명했고 RL-QT 활용에 대해 장/단점을 설명하여 이 분야에 전반적인 이해를 돕기를 바란다고 하며 결론을 짓고 있다