{kind=link}
loss가 최소가 되도록 만드는 것이 실제로 가장 이상적인 경우인가?
Cs231n 7-1. Optimization 여기서 loss가 최소가 되도록 weight를 조정시켜 optimization이 된 것을 알아보았다. 하지만 그렇다고 실제로 성능이 좋을지는 알 수가 없다.
현재까지는 training data에 대해서 loss를 최소화시키는(optimization 최적화) 방법에 대해서 배웠는데 결과적으로는 training data에서 loss를 줄여도 새로운 data에서 성능이 좋아야한다. 그렇기 때문에 처음보는 data에 대해 성능을 어떻게 높일지 evaluation과 regularization을 통해 알아보고자 한다.
Evaluation
우리가 모델을 만들어 궁극적으로 도달할 목표는 새로운 데이터가 들어왔을 때의 성능을 최대화하는 것이다! training set과 validation set의 정확도의 gap을 바꾸는게(차이가 너무 클때는 줄이고, 작을때는 늘리는 것) 목표는 아니지만 밀접한 관계가 있다.
Model Ensemble
Ensembleensemble 여러가지 의존적이지 않는 model을 각각 학습시켜 이들의 prediction을 평균내는 방법으로 급격한 성능의 향상을 보장하지는 않지만, 안정적인 성능을 보여 대부분의 딥러닝 학습에서 사용이 된다. ensemble에 들어가는 모델의 수가 늘어날 수록 performance는 꾸준히 상승하며 이때 hyperparameter가 모델마다 달라도 상관없다. 이를 통해 input 특정한 feature에 의존하는 현상을 해결할 수 있다.
Ensemble 만드는 방법: 요약을 하자면 다음과 같은 방법들이 존재한다.
- Same model, different initialization:Cross_Validation 을 이용해 최적의 hyperparmeter 구함
- 변동성이 initalization 밖에 없기 때문에 문제가 될 수 있음
- Top models discovered during cross-validation
cross validation을 통해 최고의 모델을 찾음- hyperparameter을 바꿔가면서 가장 성능이 좋은 모델들을 뽑아 ensemble에 넣음
- validation에 성능이 좋더라도 실제 최적이라는 보장 없기 때문에 항상 가장 좋은 모델이 아닐 수도 있음
- Different checkpoints of a single model
- 단일 모델에서 각 단계마다
snapshot을 찍어 이것들을 합쳐 ensemble을 만듦 - training이 매우 비싸고 어려울 때 사용하는데 성능이 나름 괜찮음
- 단일 모델에서 각 단계마다
- Running average of parameters during training
- 평균을 사용하여 변동성을 줄이고 극값 주변을 맴돌며 최적점을 찾게 됨
다만, 각각의 모델을 학습시키는 방법이 이외에도 하나의 모델을 학습을 시킬 때 여러개의 snapshot을 저장하여 ensemble 효과를 만들어 낼 수 있다. 즉, 특정 epoch마다 snapshot을 찍어 모델을 저장하여 이 모델들의 평균을 통해 예측을 진행하며 ensemble의 효과를 가져옴과 동시에 시간과 비용면에서 강점을 가지는 방법이다.
또한 아래 그림과 같이 하나의 모델에서 learning rate를 매우 빠르게 하거나 느리게 조절하여 각 모델(snapshot)마다 다른 최적점에 도달하게 만들어 이것들을 ensemble하는 방법도 존재한다.
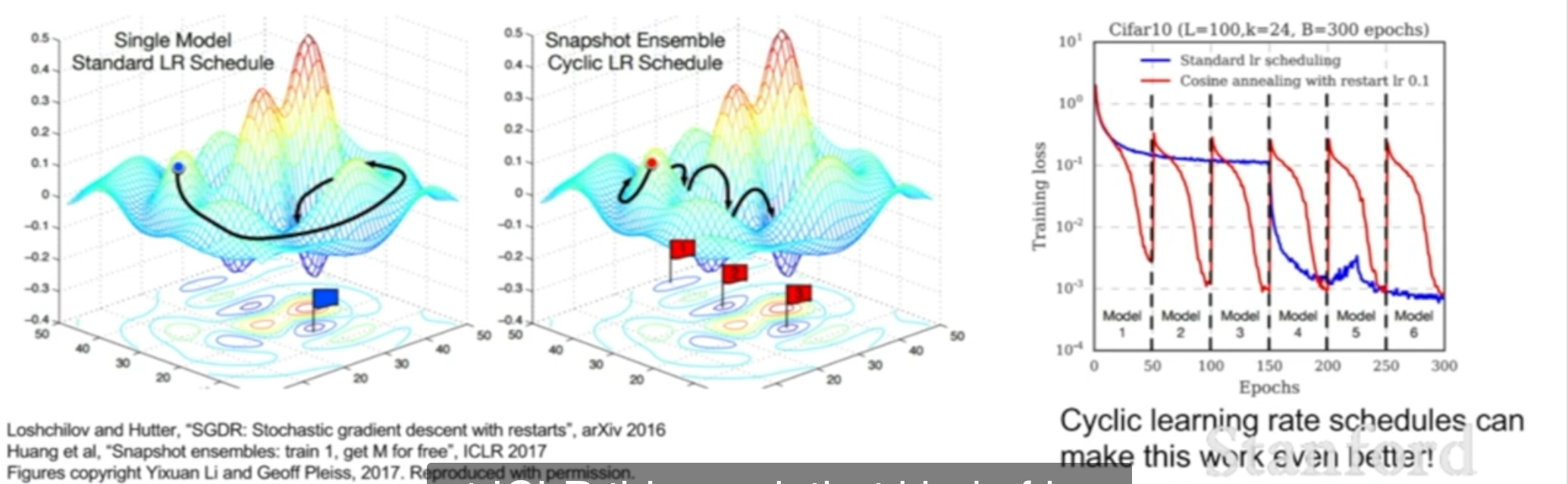
또 다른 방법으로는 Polyak Averaging(Exponential Moving Average가 존재한다. 이는 훈련 중 여러 단계에서의 모델 parameter값을 평균하여 최종 모델을 만드는 기법이다. 각 훈련단계에서 모델의 parameter을 다음과 같이 업데이트하여 최근 parameter에 얼마나 많은 가중치 를 둘지 정한 뒤 지수이동평균(EMA)를 구한다. 최종적으로 평균된 parameter을 모델로 사용하여 훈련 시간을 줄이고 진동을 평균화하여 안정적인 성능을 내게 할 수 있다.
Regularization
ensemble은 여러 모델을 합쳐 성능을 높이는건데, 그렇다면 각각의 모델은 성능을 어떻게 높일까?
Regularization은 train과 test error 사이의 gap을 줄이는 역할을 하는데 이는 곧 과적합(overfitting)을 줄여 새로운 데이터가 들어왔을 때 모델의 단순함을 통해 적절한 예측을 할 수 있도록 만든다. 이때 loss function에 추가적인 regularization항의 추가를 통해 구현이 된다. CS231n 2-3 Linear Classification(Regularization)regularization
결국 중요한 것은 train set에서의 정확도가 아니라 test set에서의 정확도이므로 loss항과 regularization항 사이에 균형점을 찾아, 충분한 학습과 함께 모델의 간단함 모두 가지는 것이 중요하다.
1. Dropout
p의 확률로 neuron이 active될지가 정하는 방법으로 regularization이 가능하게 만든다. 결국 더 간단하게 모델을 만드는 것이 목표이므로, 특정 class를 분류하는데 사용하지 않는 neuron들은 이용하지 않음으로써 과적합을 맞고 필요한 특성들만 사용하게 만드는 방식이다 ! 5. Dropout and Batch Normalization
주로 fully-connected layer에서 사용이 되지만 convolutional layer에서도 특정 feature map 전체를 사용하지 않거나(ex: 3번째 filter로 나온 결과를 drop) 특정 channel을 사용하지 않음으로써(ex: RGB channel 중 R channel을 drop) 공간적 정보는 유지한채 dropout을 구현이 된다.
작동 방식
- 일부 노드의 activation을 random으로 0(non-active)하게 만들어 노드 스위치를 끔
- 매 epoch(과정)마다 무작위하게 꺼지는 노드들이 달라짐
- 이후 test때는 dropout을 진행하지 않는데, test때는 특정 input이 정확히 무엇인지를 알아야 하고 무작위하게 뽑아 결과를 도출할 경우 같은 input에 매번 다른 ouput이 나올 가능성과 이것을 적분을 이용해 평균을 내는 것이 어렵기 때문이다.
- test output에 p를 곱해야 training한 애들과 같은 값을 가져 정확한 분류가 가능하므로 만큼 곱해야하고 이는 적분을 이용해 평균을 내는 것이 어렵기 때문에 근사한 방법이다. 혹은 training을할 때 dropout한 결과에 를 나눠 test할 때 를 곱하지 않아도 되게 만들 수도 있다..

장점
- 학습과정에서 redundancy(중복성) 를 줄임
- 남은 노드들끼리 섞어가면 학습하여 각 노드의 정확도 및 영향력을 높이고 특정 feature에 의존하는 것을 막고, 오히려 여러 feature에 분산하는 효과를 가진다.
- 또한
randomness를 추가하게 됨으로써 과적합을 줄이는 효과를 가져온다.
- overfit과 underfit를 해결 가능
- overfitting 인 경우 p값을 늘려 무작위성을 늘림으로써 더 적은 수의 노드 사용하여 해결
- underfitting 인 경우 p값을 줄여 무작위성을 줄임으로써 더 많은 수의 노드를 사용을 사용하여 해결
- 일종의 ensemble 방식의 효과를 가진다.
- 또 다른 해석으로는 같은 parameter을 가지는 모델들의 큰 ensemble이라고 보는데, 각 dropout 때마다 network의 구조가 달라지게 되게 되고 이로 인해 여러 모델들을 합친 것으로 볼 수 있기 때문이다.
- 시간이 오래걸리지만 모든 randomness한 결과를 합친다는 점에서 일반화에 강점을 보이며 regularization 효과가 있는batch_normalization 과 유사점을 가진다. CS231n 6-2. Setting Up the Data and the Loss
batch normalization은 결과를 전체의 평균으로 내는 것이 아니라 mini batch에서 내며, 를 움직여 값 조정이 불가하다.dropout의 경우 특정 neuron만 sample되어 학습이 진행되기 떄문에 모든 neuron이 학습을 하는데에 오랜 시간이 걸릴 수 밖에 없다. 이때 training 때는 무작위성의 추가를, test에서는 무작위성을 평균을 냄으로써regularization을 구현한다.batch normalization역시 training때는 무작위한 minibatch들을 normalize하고 test때 전체적인 값들을 normalize한다는 점에서dropout과 유사하며, 실제로batch normalizaiton을 사용한 경우dropout을 굳이 사용하지 않기도 하다
2. Data augmentation
Regularization의 일종으로 data의 label을 바꾸지 않고 train data를 변형을 줘서 구현 가능하다. 즉, input 데이터의 개수를 더 늘림으로써 과적합을 줄이고 모델의 성능을 증가시키는 방법이다.ResNet 에서 사용한다.
- 사진 좌우반전(horizontal flip)
- 사진을 랜덤하게 자르기(random crop)
- 사진의 크기 바꾸기 (random scale)
- 색의 밝기 및 대비 바꾸기(contrast, brightness)
이외 방법들
- DropConnect: activation을 0으로 만드는 것이 아니라 weight matrix를 0인 행렬로 만드는 것으로 dropout과 비슷한 효과를 가져온다
- fractional Max pooling: 각
pooling layer에서 무작위하게 어떤 지점을 max pooling할지를 정하는 방법으로 test때 이것들의 평균을 구하는 방법으로 자주 사용되지는 않지만 멋진 방법이다 - Stochastic depth: layer을 아예 drop 하는 방법으로 후에 다시 다룬다 CS231n 9. CNN Architecturesstochastic_depth
regularization은 주로 batch normalization으로 충분하지만 일부 overfitting이 과한 경우 dropout을 추가할 수 있다. 즉, 일단 과적합이 되는지 확인해보고 과적합일 경우 어떤 regularization을 추가할지 정하면 된다.
Training Transferring
transfer_learning :학습할 data가 많지 않아 과적합 되는 경우에 사용하는 방법이다. 사실 과적합이 생겼을 때 가장 좋은 방법은 데이터 수를 늘리는 것인데 이것이 매우 어렵기 떄문에 위에 방법들 등으로 주로 해결한다. 하지만 데이터가 매우 부족하여 위에 방법들도 소용이 없고, 특히 데이터가 많이 필요한 CNN의 경우는 transfer learning을 사용하는 것이 효과적일 수 있다.
이런 방법은 CNN에서 매우 자주 사용되고 만연해 있으며 일반적인 방법이다. 대부분의 경우 처음부터 CNN을 설계하고 만들지 않고 다음과 같이 transfer learning을 사용한다. 실제로 프로젝트를 진행할 때 이 방법을 사용해보는 것이 좋다.
학습 순서
- 많은 양의 데이터로 학습시킨 알고리즘을 가져옴
- 적은 클래스를 분류하는 알고리즘을 만들고 싶은데 데이터도 적은 경우 맨 마지막 FC layer만 weight들을 초기화하여 C개의 score을 내보내도록 바꾼다. 이후 갖고 있는 작은 데이터셋을 이용해 class score을 도출하고 학습을 진행시킨다.
- 데이터의 양이 조금 더 많다면 좀 더 상위 layer까지 초기화한 후 다시 학습을 진행한다.
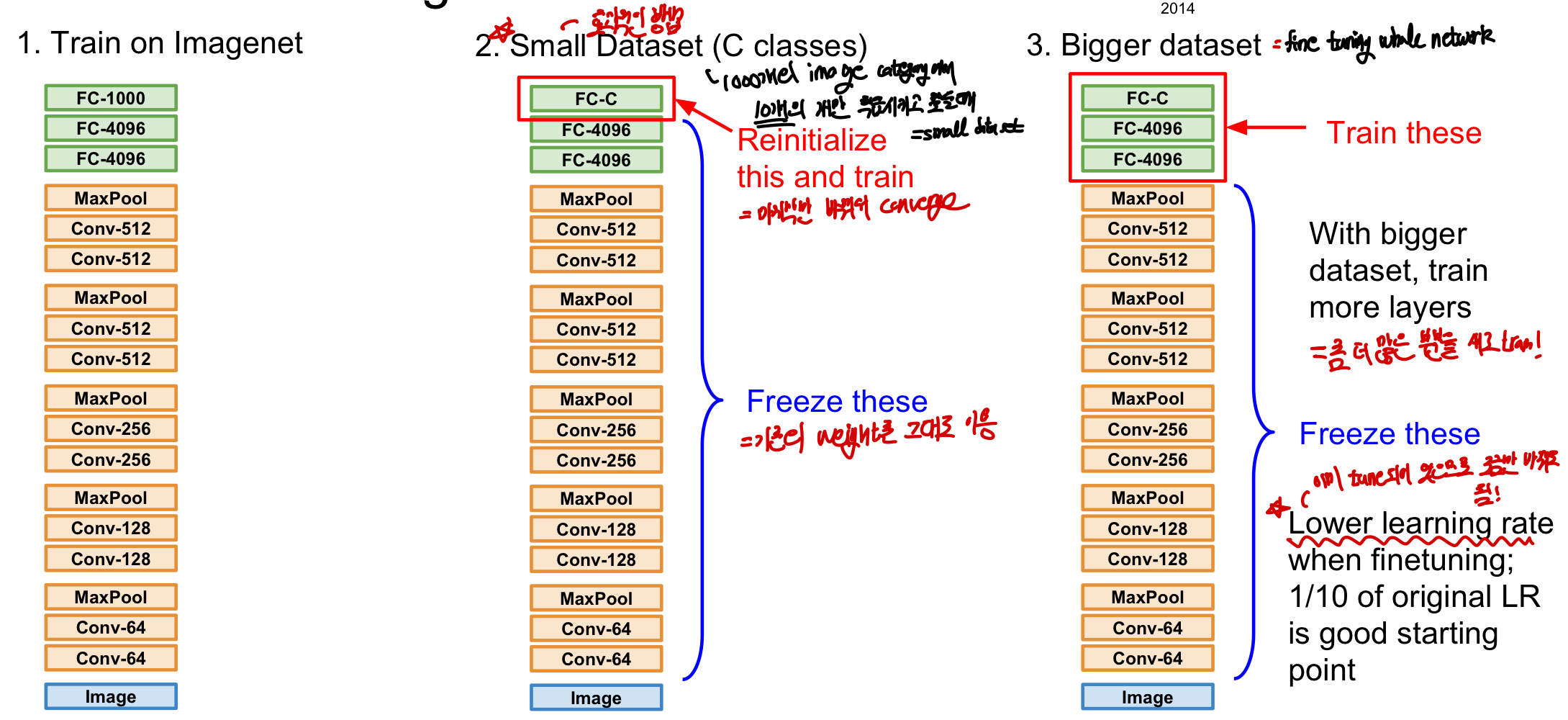 이미 학습이 되어 있기 때문에 learning rate를 줄여도 되며 단, 모델이 학습한 것과 비슷한 dataset에 대해서만 적용이 가능하다. (예를 들어 이미지 분류를 하는데 글자인식의 data를 넣으면 안된다.) 기존의 학습한 지식을 가지고 dataset의 크기를 줄이는 방법이며 특히 매우 비슷한 데이터셋에 대해서 조금의
이미 학습이 되어 있기 때문에 learning rate를 줄여도 되며 단, 모델이 학습한 것과 비슷한 dataset에 대해서만 적용이 가능하다. (예를 들어 이미지 분류를 하는데 글자인식의 data를 넣으면 안된다.) 기존의 학습한 지식을 가지고 dataset의 크기를 줄이는 방법이며 특히 매우 비슷한 데이터셋에 대해서 조금의 finetuning을 이용해 쉽고 정확한 모델의 생성이 가능하다. 다만 다른 데이텟이더라도 데이터의 양이 많다면 더 많은 layer을 재학습시킴으로써 성능을 향상시킬 수 있다.
