{kind=link}
learning algorithm을 실제 문제에 적용을 할 때 “데이터를 많이 모으는 것이 중요하다고 생각될 때만 데이터를 구하는데 시간을 많이 써라!” 라는 말이 존재한다. 당연하다고 생각할 수 있는 말이지만 실제로 프로젝트를 진행하고 데이터를 더 모아야할지, 혹은 알고리즘을 변경해야할지에 대한 결정들이 필요할 때 어떤 근거로 결정을 내릴지에 대해서 알아보고자 한다. 참고로 이 강의에서 다루는 방법들은 ML과 관련된 논문을 쓸 때 가장 이상적인 방법은 아닐 수 있다는 것을 알아야한다.
Debugging ML Models
Machine Learning Model들의 성능의 문제가 생겼을 때 어떻게 해결해야할지를 systematic하게 결정하도록 만들 것이다! 맨 처음에 learning algorithm을 만들게 되면 제대로 동작이 하지 않을 것이다. 이럴 때 그 다음에 어떻게 할지 정하는게 효율성의 측면에서 매우 중요하다.이런 측면에서 debugging 전략이 중요하다!
Strategy!
메일이 spam인지에 대한 문제에서Bayesian 학파의 maximum likelihood와 regularization term을 추가한 logistic regression을 사용한다고 가정한다. 이때 20%의 test error가 발생했다면 그 다음에 어떻게 해야할까? 알고리즘을 발전시키기 위해 여러가지 방법을 사용해야한다!
- 더 많은 training example들을 모은다 (대부분의 경우 도움이 되지만 얼마나 모을지가 문제)
- 더 적은 feature set을 이용
- 더 많은 feature set을 이용
- 다른 종류의 feature을 사용 (email내의 내용이아닌 email의 header 정보를 feature로 사용)
- 더 많은 iteration을 통해 gradient descent를 진행
- Newton_method 사용
- 다른 의 값을 사용
- SVM 알고리즘을 사용
대부분의 경우 이러한 전략중에 하나를 무작위로 정해 시도해본 후 다른 방법을 시도하여 알고리즘을 발전시킨다. 하지만 어떤 것이 가장 최선의 방법일지 모르는 것이 문제이기 때문에 이럴 때 가장 흔하게 사용되는 해결책(diagnostic)이 바로
Bias VS Variance Diagonstic이다.CS229 8. Data Splits, Models & Cross-Validation
1. Bias VS Variance Diagonstic
알고리즘이 문제인 경우는 크게 high bias와 high variance인 경우이다. 아래는 bias와 variance가 높고 적은 것에 대한 parameter의 관점에서 표현한 그림으로 자세한 것은 CS229 9. Approx, Estimator Error & ERM을 참고하면 된다. 요약하자면 high bias는 제대로 학습을 하지 못한 경우이고, high variance는 너무 복잡하게 학습을 한 경우이다. 즉, training set의 크기를 늘렸을 때 graph를 보고 high variane와 high bias인 경우를 구별하여 상황에 맞는 조취를 취하면 된다!
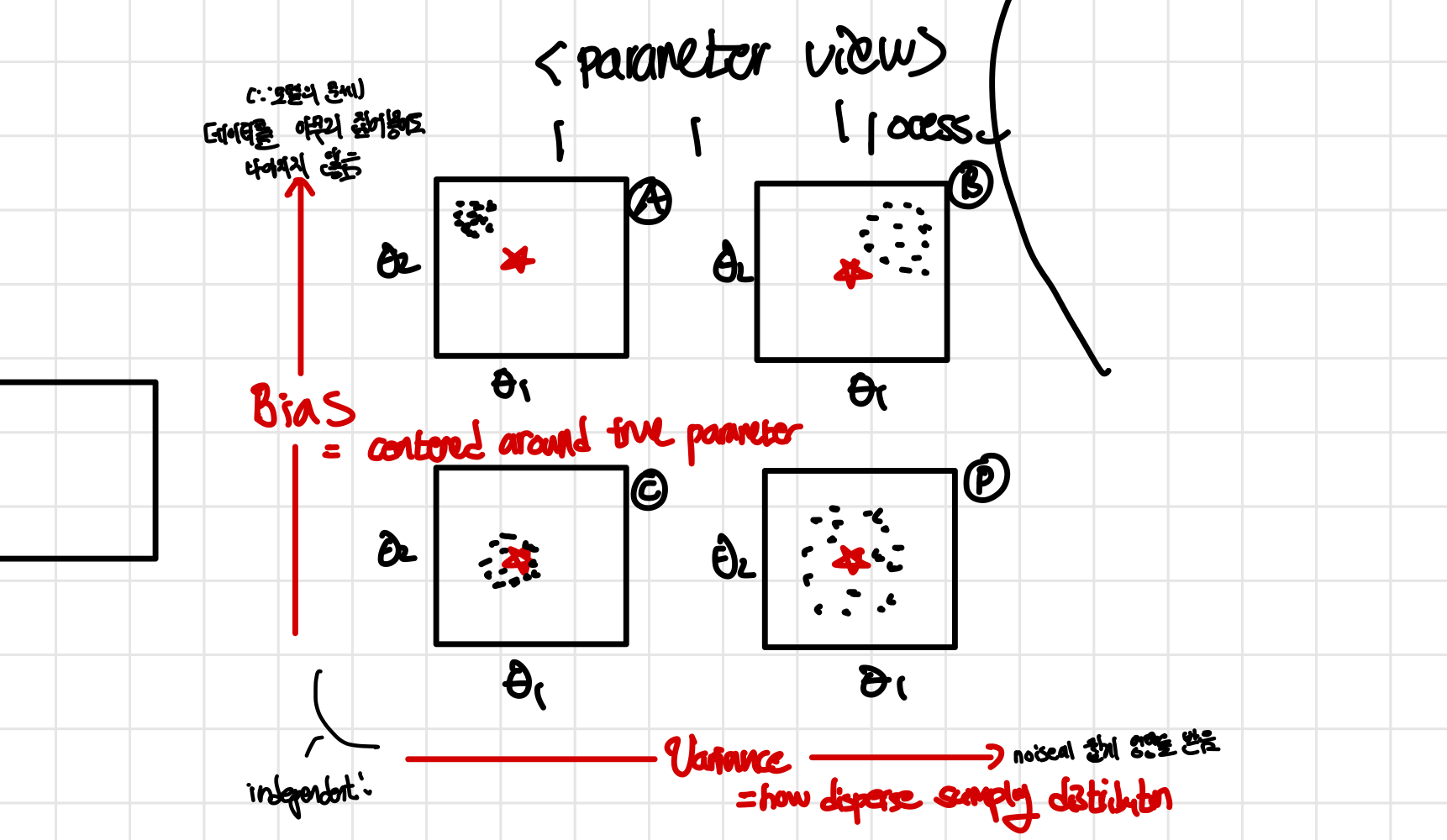
 즉, 문제가 bias에서 오는지, variance에서 오는지를 구별하여 이에 맞는 해결책을 제시하면 되는 것이다. 위에서 가정한 예시에서 high variance와 high bias인 경우에 대해서 따로 생각을 해보자!
즉, 문제가 bias에서 오는지, variance에서 오는지를 구별하여 이에 맞는 해결책을 제시하면 되는 것이다. 위에서 가정한 예시에서 high variance와 high bias인 경우에 대해서 따로 생각을 해보자!
High Variance
high variance인 경우에는 training error가 test error에 비해서 매우 아래에 있는 것이 특징이다. test error가 떨어지는 것만으로 high variance이라고 판단하기 어렵기 때문에 더 강력하고 확실하게 high variance인 경우라고 판단할 수 있는 것이 training error와 test error 사이의 차이이다.
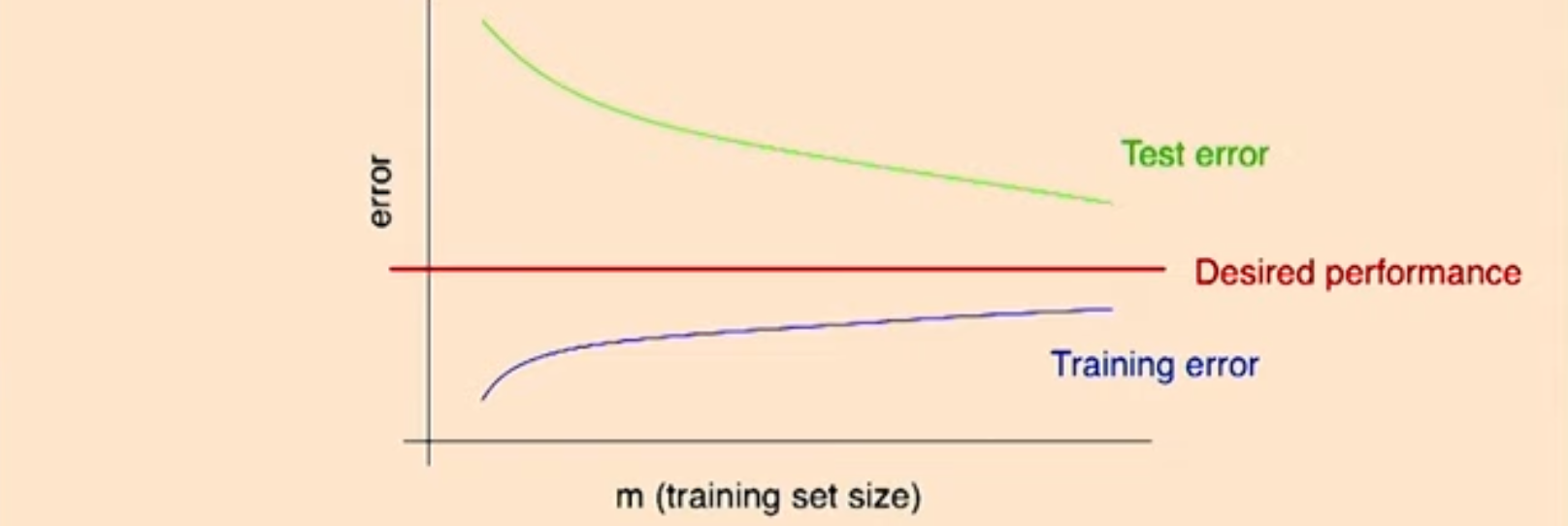 이때 training set의 사이즈가 커져, example들이 더 많아지게 된다면 high variance에서 test error는 점점 줄어드게 된다. 이 이유에 대해서는 CS229 9. Approx, Estimator Error & ERM에서 자세히 다루고 있다. 참고로 이때 desired performance는 주로 사람이 직접 분류했을 때의 성능을 말하며 문제 상황에 따라 달라질 수 있다
이때 training set의 사이즈가 커져, example들이 더 많아지게 된다면 high variance에서 test error는 점점 줄어드게 된다. 이 이유에 대해서는 CS229 9. Approx, Estimator Error & ERM에서 자세히 다루고 있다. 참고로 이때 desired performance는 주로 사람이 직접 분류했을 때의 성능을 말하며 문제 상황에 따라 달라질 수 있다
반면에 training error를 example이 많아질 수록 error가 증가하게 된다. 이는 만약에 하나의 example만 존재할 경우 어떤 알고리즘이든지 완벽하게 학습이 가능하게 되고 이와 마찬가지로 training set이 작을 경우 error가 0에 수렴하기 때문이다. 반면에 training set의 크기가 커질 경우 모든 경우에 알맞게 학습을 하지 못하기 떄문에 error가 생기게 된다. (linear regression에서 1,2개는 완벽히 분류가능하지만 많아질 경우 그렇지 못함)
test error(green line)의 감소속도가 어떻게 될까?
위에서의 그래프는 training data가 IID을 가정한 것 처럼 보이며 training,dev,test set들이 모두 같은 distribution에서 나왔다고 볼 수 있다. 이때 learning theory에서 대부분의 경우 test error는 bayes error에 도달하기 전까지로 줄어들게 된다. 하지만 leaning algorithm error는 주로 0으로 가지 않는데, 이는 input example 자체의 문제가 있어 주요 feature들을 가지고 있지 않아 error가 생길 수밖에 없기 때문이다.
High Bias
training error도 같이 높은 것이 특징이며 training error와 test error간의 차이가 적다. 즉, test error와 training error의 차이가 적고 모두 error가 높다는 것을 통해 알고리즘이 제대로 학습을 하지 못하고 있다는 것을 파악하여 high bias라는 것을 알 수 있다
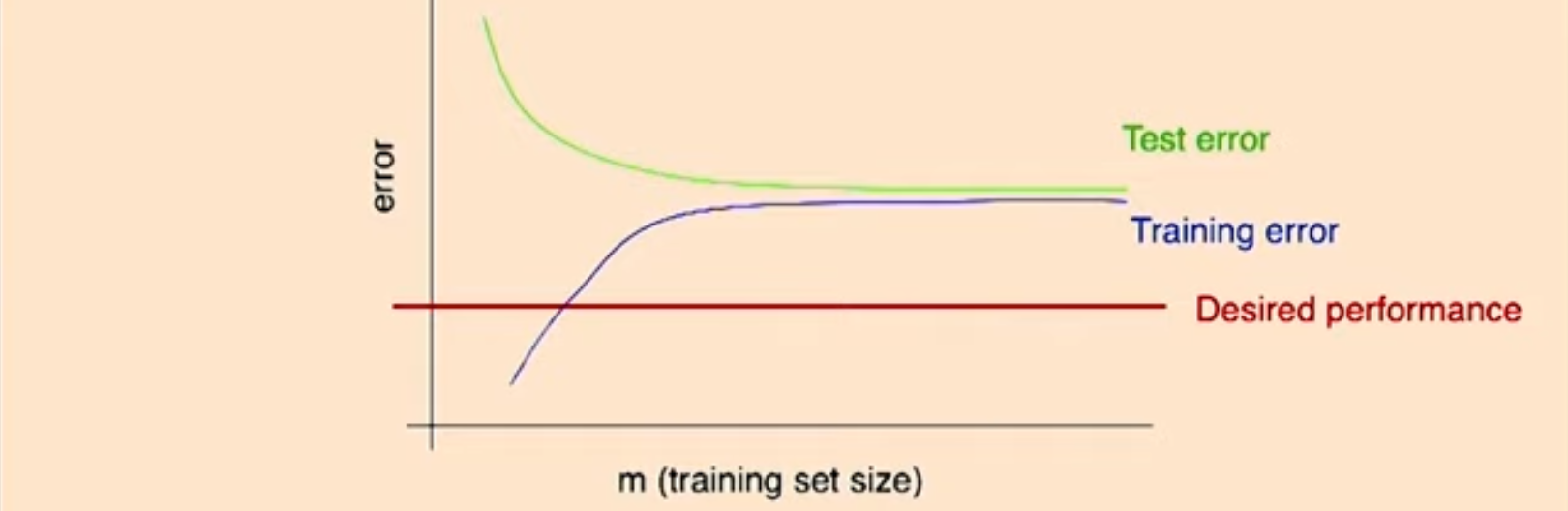 전의 강의들에서 언급한 것과 같이 bias는 training set의 크기(example들의 수)와는 크게 관련이 없는데, 주로 알고리즘 자체의 학습에 문제이기 때문에 set의 크기를 늘린다고 해서 error가 줄어들지 않는다. 그렇기 때문에 test error가 높을 뿐 아니라 training error가 높다.
전의 강의들에서 언급한 것과 같이 bias는 training set의 크기(example들의 수)와는 크게 관련이 없는데, 주로 알고리즘 자체의 학습에 문제이기 때문에 set의 크기를 늘린다고 해서 error가 줄어들지 않는다. 그렇기 때문에 test error가 높을 뿐 아니라 training error가 높다.
Fix Strategy!
- 더 많은 training example 모으기 ⇒ Fixes High Variance
- 더 적은 feature set을 이용 ⇒ Fixes High Variance (알고리즘을 간단하게!)
- 더 많은 feature set을 이용 ⇒ Fixes High Bias (알고리즘이 너무 단순해서 학습을 못했기 때문에 복잡하게!)
- 다른 종류의 feature을 사용 ⇒ Fixes High Bias (제대로 학습을 못했기 때문에 다른 feature을 사용!)
실제로 문제에 사용을 할 때 맨 처음에 빠르면서도 더러운(quick & dirty) 알고리즘을 적용하고 bias-variance analysis를 통해 무엇이 잘못되었는지 확인한 후 그 다음에 무엇을 할지 정하는 것이 좋음!(더 복잡한 알고리즘을 사용할 것인지, 더 많은 data들을 모을 것인지 etc..) 물론 탐구하고자 하는 분야에 대해서 배경지식이 존재하고 어떤 알고리즘을 사용할 것인지, 얼마나 많은 데이터가 필요할 것인지 대략적으로 알고 있다면 이런 방식을 채택할 필요는 없지만 새로운 분야에 적용을 할 떄는 이 방법이 중요하다.
2. Optimization Algorithm Diagnostics
예를 들어, logistic regression은 spam과 non-spam 모두 2%의 오류를 갖는 반면(non-spam에 대해서 높은 error, 중요한 메일을 버리게 됨), SVM+kernel은 spam mail에는 10%, non-spam mail에는 0.01%의 오류(non-spam에 대해 낮은 error)를 갖고 있다고 가정할 때 연산효율성 때문에 logistic regression을 사용하고 싶다면 어떻게 해야만 할까?
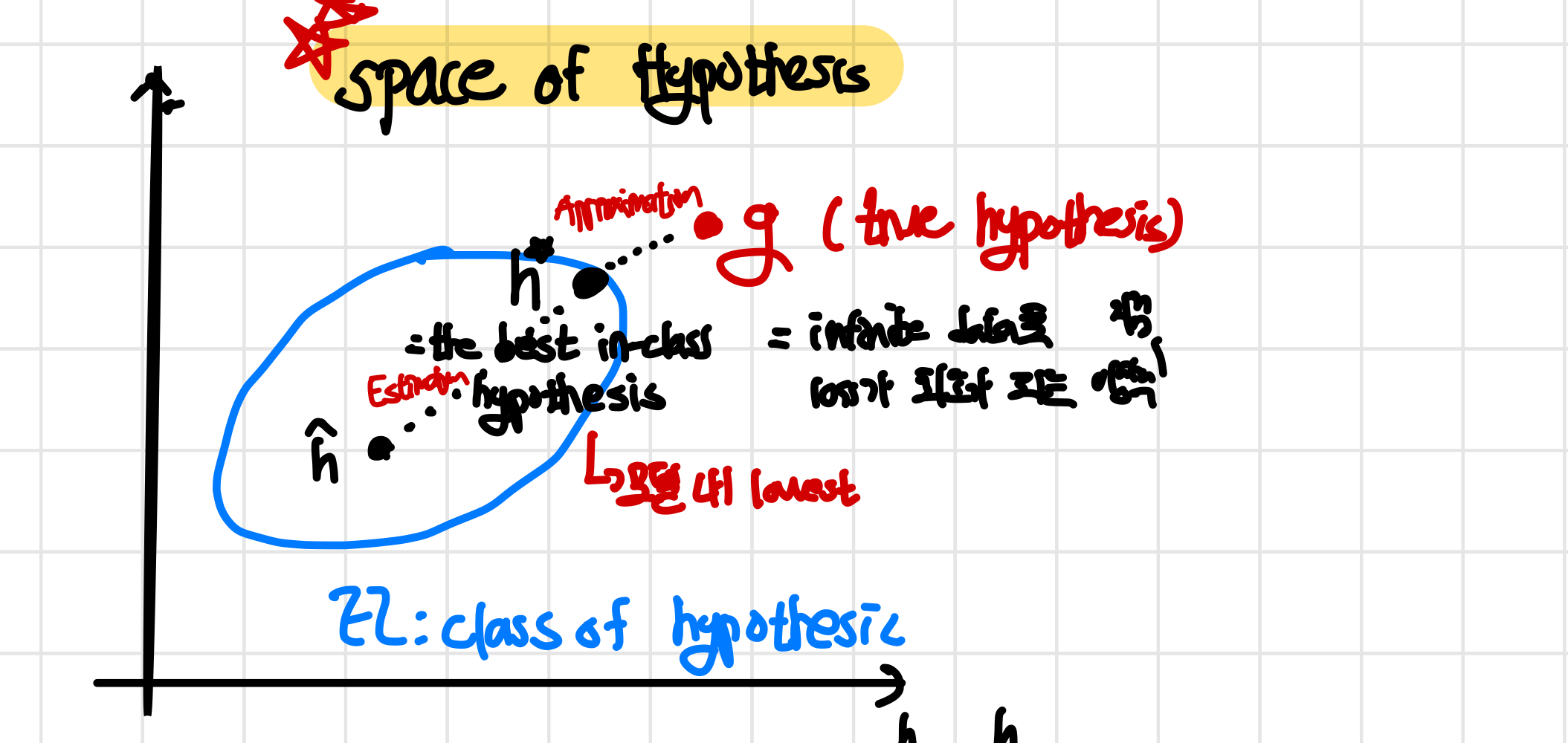
이때 weight w를 이용한 정확도를 과 같이 정의를 하고 SVM에 의해 학습된 parameter을 , Bayesian logistic regression에 의해 학습된 parameter을 이라고 할 때 이 예시에서 이 보다 더 좋은 성능을 보이기 때문에 이라고 할 수 있다.
왜 를 직접적으로 학습시키지 않음?
이 정확도를 나타내는 함수는 미분이 불가능하여 gradient ascent를 진행할 수 없어 최적화를 시킬 수 없기 때문에 loss(cost) function을 이용하여 대신 정확도를 알아보는 것이다! 또한 이 정확도를 최대화시키는 것이 NP-Hard로 알려져있다.
Algorithm converging?
첫번째로 중요한 질문이 과연 알고리즘이 최적의(optimal) 지점으로 수렴(converge)하느냐이다. 즉, iteration이 증가하면서 objective function 가 증가를 해야하지만 수렴(converge)한다고 말할 수 있다. 하지만 objective function만 바라봄으로써 알고리즘이 수렴하는지 알기 위해서는 많은 시간들이 필요하다는 문제점이 존재한다. 1) 만약 이라면 이 function J를 최대화하는데 실패했기 때문에 알고리즘이 최적의 지점으로 수렴(converge)하지 못했다는 뜻이 되고 이를 problem is with optimization algorithm이라고 일컷는다.
Right Function?
두번째로 중요한 질문이 바로 과연 올바른 함수를 이용하여 최적화를 진행하고 있는지이다. 실제로 고려해야하는 것은 정확도인데 이를 식으로 쓰게 된다면 과 같이 나온다. 하지만 logistic regression에서는 cost function을 최대화하는 것이 목표이고 이때 알맞는 역시 알고싶다. logistic regression의 식은 다음과 같다 즉, 실제 cost function(loss function)을 최적화했을 때 그 결과가 실제 정확도를 향상시키지 않을 경우 를 바꾸거나 아예 새로운 알고리즘의 objective function으로 바꾸어(SVM..) 다른 cost function을 사용하여야 한다 2) 만약 일 때는 이 function J를 최대화하는데 성공을 했지만 weighted accuracy가 SVM보다 안좋은 경우이기 때문에 function J가 잘못된 함수라는 것을 알 수 있으며 이를 problem is with objective function of the maximization problem이라고 일컷는다.
Fix Strategy
- 더 많은 iteration을 통해 gradient descent를 진행 ⇒ Fixes Optimization algorithm
- Newton method 사용 ⇒ Fixes Optimization algorithm
- 다른 의 값을 사용 ⇒ Fixes Optimization objective / Bias & Variance
- SVM 알고리즘을 사용 ⇒ Fixes Optimization objective
Helicopter Example
여기서는 어떻게 error가 나오는지를 알아보고 해결방안을 알기 위해 무인 헬리콥터의 예시를 통해 설명하고자 한다. 무인 헬리콥터가 학습하여 비행하는 단계는 아래와 같다.
- 헬리콥터의 시뮬레이터를 만든다 (컴퓨터내)
- cost function을 선택한다 (여기서는 간단하게 로 계산)
- reinforce_learning 알고리즘을 통해 시뮬레이션 내에서 헬리콥터를 날려, cost function을 최소화시킨다. ()
다음과 같은 단계를 거친 후에 결과로 나온 parameter 이 인간의 조종사보다 더 안좋은 성능을 보였을 때 어떻게 해야할까? 직관적으로 생각해보면 헬리콥터가 학습하는 단계에서 각각의 성능을 높이면 되는데 그 기준이 어떻게 되는지 알아보자!
Debugging Process
만약 1) 헬리콥터 시뮬레이터가 정확하고 2) 알맞은 cost function을 선택하여 3) function J를 최소화시킬 수 있다면 실제 무인 헬리콥터에서도 제대로 비행이 되어야할 것이다. 이때 우리는 간 단계를 하나씩 확인하여 어디가 문제인지 알아볼 것이다
- 만약 이 시뮬레이션 내에서는 잘 날아다니지만 실제 세계에서는 그렇지 못할 때 문제는 시뮬레이션이다(주로 시뮬레이션에 최대한 실제와 비슷하게 만들기 위해 noise를 많이 추가하게 되는데 이 때문에 시물레이션에서는 안되지만 실제 셰계에서 될 수도 있지만 거의 없음)
- 을 인간이 조정한 policy라고 할 떄 만약 이라면 cost function을 최소화하는데 실패했기 떄문에 문제는 RL 알고리즘에 있다는 것을 알 수 있다. (Fixes Optimization Algorithm)
- 만약 이지만 실제 환경에서 날 수 없다면 cost function을 최소화하는 것이 곧 정확한 비행을 할 수 없다는 것을 의미하기 때문에 cost function의 문제가 있다고 볼 수 있다(Fixes Optimzaiton object) 다음 과정들을 계속해서 반복하여 error들을 분석하고 이를 통해 제대로 학습과 실행을 가능하게 만든다
Error Analysis
만약 얼굴 인식 알고리즘을 만들고자 할 때 어떻게 error를 분석할지에 대해서 알아보자
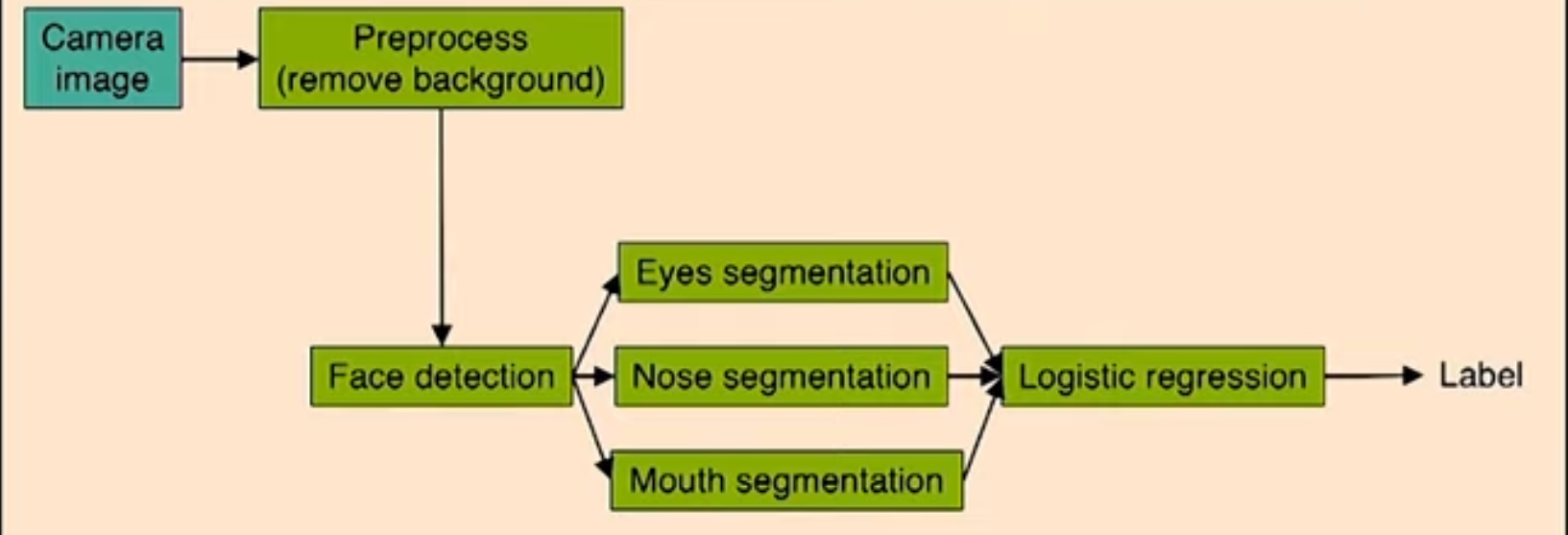 다음과 같이 얼굴 인식 알고리즘이 진행이 된다. 맨 처음에 카메라가 찍은 이미지에서 배경을 없앤 뒤에 사람의 모습만 인식할 수 있도록 만든다. 후에 사람의 얼굴을 탐지할 수 있게 만들고 눈,코,입 등을 따로 인식하고 분류하여 하나의 새로운 feature로 생성함으로써 이를 통해 logistic regression을 진행하게 된다. 이 과정을 거치면서 얼굴을 인식하는 알고리즘을 생성 가능하다. 하지만 이 pipeline에서 error가 생겼을 때 어느 부분을 확인하는 것이 좋은 방법일까?
다음과 같이 얼굴 인식 알고리즘이 진행이 된다. 맨 처음에 카메라가 찍은 이미지에서 배경을 없앤 뒤에 사람의 모습만 인식할 수 있도록 만든다. 후에 사람의 얼굴을 탐지할 수 있게 만들고 눈,코,입 등을 따로 인식하고 분류하여 하나의 새로운 feature로 생성함으로써 이를 통해 logistic regression을 진행하게 된다. 이 과정을 거치면서 얼굴을 인식하는 알고리즘을 생성 가능하다. 하지만 이 pipeline에서 error가 생겼을 때 어느 부분을 확인하는 것이 좋은 방법일까?
만약 각 단계를 완벽하게 처리했을 때 (예를 들어, 포토샵으로 background를 완전히 없앴을 때)의 성능을 구해 어떤 부분이 중요한 역할을 하는지 알아내는 방법이 있다.
예를 들어, image가 그대로 넣었을 때 정확도가 85%이고, background를 없앴을 때 85.1%, face detection 부분이 91%, eyes/nose/mouth detection이 각각 95%,96%,97% logistic regression까지 한 경우는 100%라고 하자. 그렇다면 여기서 알 수 있는 것은 정확도가 얼마나 증가했는지에 따라 어떤 부분이 중요한지 알 수 있는데, 여기서는 background를 없애는 것은 별로 중요치않고, face detection을 하는 것이 정확도를 많이 증가시키기 때문에 이 부분에 시간을 많이 투자하는 것이 좋다.
다만 이것은 누적된 결과이기 때문에 순서를 바꿔서 진행하거나 합칠 수 있는데, 이 경우에도 비슷한 결과를 내보낼 확률이 높다.
Ablative Analysis
또 다른 error analysis 방법이 바로 ablative(탈격) analysis로 시스템에 있는 구성요소들을 한번에 하나씩 없앰으로써 정확도가 어떻게 달라지는지 확인하는 방법이다.
