{kind=link}
Summary
K-NN알고리즘 문제점으로 인해 나온 해결책이 Linear Classification으로 parameter을 이용하여 score function과 loss function을 통해 학습이 가능하며 test 시간을 줄일 수 있게 됐다. 다만 하나의 linear classifier은 하나의 class당 하나의 template(하나의 weight를 통해 만들어진 값)을 가지기 떄문에 class의 다양한 사진을 구별하는데 어려움이 존재한다. (단지 평균을 취해 하나의 종합적인 template을 만들게 되는거임) 하지만 Neural Network의 기초가 되며, 가장 기본적이고 쉬운 classifier가 된다. CS231n 1. Image Classification
Linear Classification
앞으로 배울 Neural Network의 주요 블럭이 되는 것이 linear classifier로 이것들의 조합이 곧 Neural Network를 만든다고 볼 수 있다. Neural Network를 레고라고 봤을 때 linear classifier은 각각의 블럭이라고 생각을 하면 됨! 기존 kNN의 문제점: 모든 training data를 기억하여 test data와 비교해야함 & 비용이 큼(모든 trainig data를 비교해야함) 새로 발전해야할 점: Score function(raw data를 class score에 연걸) & Loss function(예측된 점수와 실제 label 간의 유사도를 수량화함) ➡️ parameter가 생기기 시작하여 이 parameter만 갖고 있다면 test 시간을 줄일 수 있다
- score function에 parameter에 관하여 loss function을 최소화하여 optimization(최적화) 진행
- neural network를 만드는데 매우 중요하며 각각을 따로 생각한 뒤 레고처럼 합치는 방식을 취함!(매우 간단하고 쉬움)
Parameterized mapping from images to label scores
- Score function 정의하기: 각 이미지의 pixel 값들을 각각의 class 점수에 mapping 시킴!
- : = Image
- = parameter / weight (CS229에서는 theta)
- : 총 N개의 이미지
- : 각 이미지의 차원성
- : 서로 다른 카테고리의 수 ⇒ 이 결과로 class score에 따른 10(K)개의 숫자가 나오게 됨
Linear classifier : 아 모듈에서는 linear mapping을 통해 함수를 만들어낸다
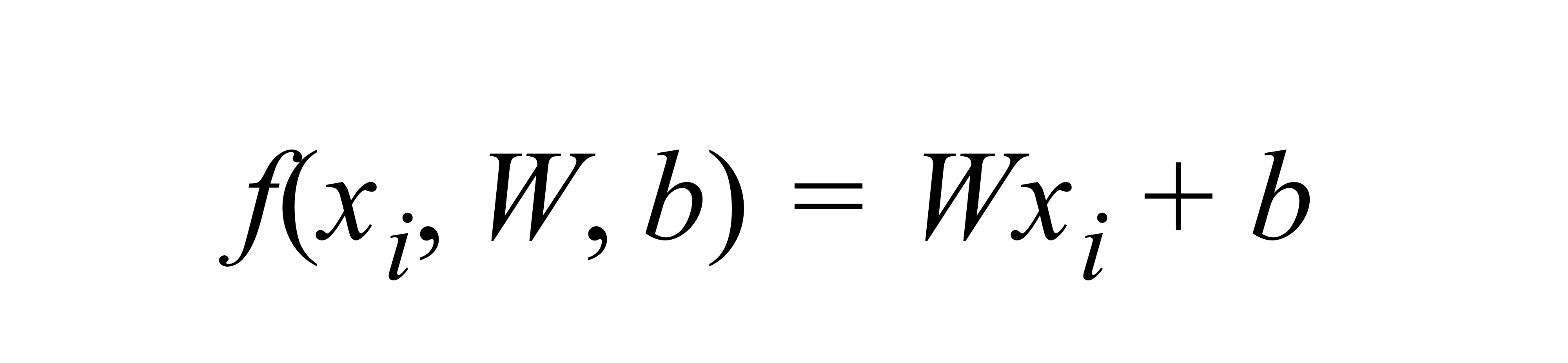
- 각 input 이미지를 뜻하며 여기서는 모양을 갖는 열 백터로 되어 있다고 가정!= 3072X1 (D=32X32X3)
- parameter
- : 10X3072의 크기로 3072개의 숫자(픽셀)가 입력으로 들어와 10개의 숫자(class score)가 출력된다(학습이 가능한 값!)
- : bias 백터로 10X1의 크기이며 실제 입력 데이터인 xi와는 아무런 상호 작용이 없이 출력 스코어에 영향을 준다(각 class마다 독립성을 보장하기 위해서 추가하는 경우가 많음) 입력데이터 (xi,yi)는 주어진 값(고정된 값) ⇐> W,b는 우리가 조정할 수 있음(parameter!) ⇒ 우리의 목표는 우리가 계산한 score이 실제 label(ground truth)과 가장 잘 일치하도록 parameter을 조절! (잘 맞춘 class가 점수가 높도록!)
training data가 W,b를 학습하는데 사용한 이후에는 필요가 없어짐! & 행렬 곱 한번으로 시간을 단축 ⇒ 새로운 데이터가 들어오면 (test data) W와 b를 이용해 계산하기만 하면 됨
A. Interpreting a linear classifier
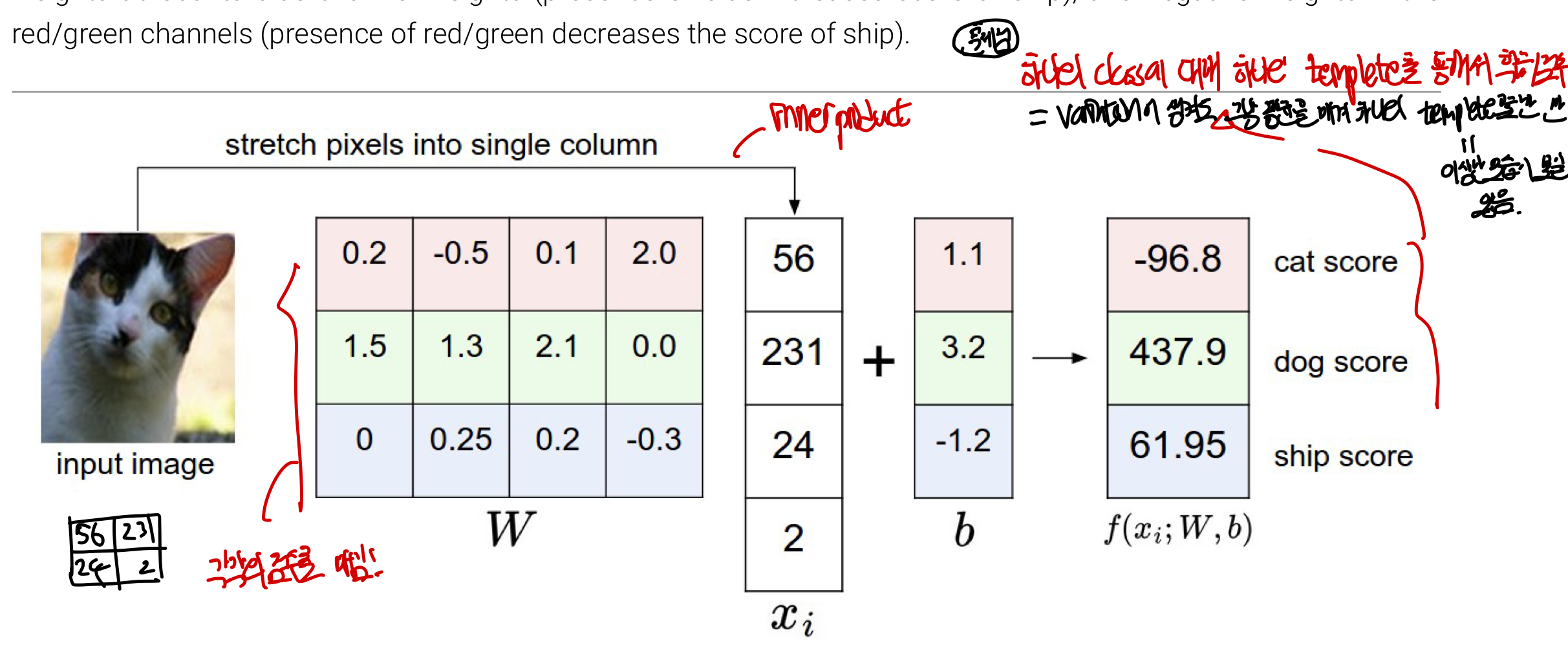
- : 사진의 픽셀들을 하나의 열백터로 만듦
- : 이 parameter/ weight를 이용해 score function을 만들어 특징들을 구별하게 만듦(즉, 값을 바꾸면서 학습이 가능함!) 즉, 각 픽셀의 특징이 특정 class와 얼마나 유사한지를 W에 넣어주고 +/-의 가중치를 이용하여 계산을 하면 됨(해당 사진이 고양이임에도 W가 고양이의 특징을 학습하지 못해 class 분류를 제대로 못하고 있으므로 W를 매우 안좋은 편이라고 생각할 수 있다.)
- CS229에서 2강(CS229 2. Linear Regression)에 배우는건 Linear Regression이어서 W를 구성하는데에 있어 약간의 차이가 있음
- 여기서 W의 차원(dimension)은 class의 개수에 의해 결정됨 variation이 생겨도 평균을 매겨 하나의template 으로만 만들게 됨(이상한 모습이 보일 수 있음)
Analogy of images as high-dimensional points
전체 데이터셋은 라벨링된 고차원 공간 상의 점들의 집합이 되며 각 이미지들을 고차원 열백터(D: 3072X1)로 만들었기 떄문에, 각 이미지를 고차원 공간상의 하나의 점으로 생각할 수 있다!
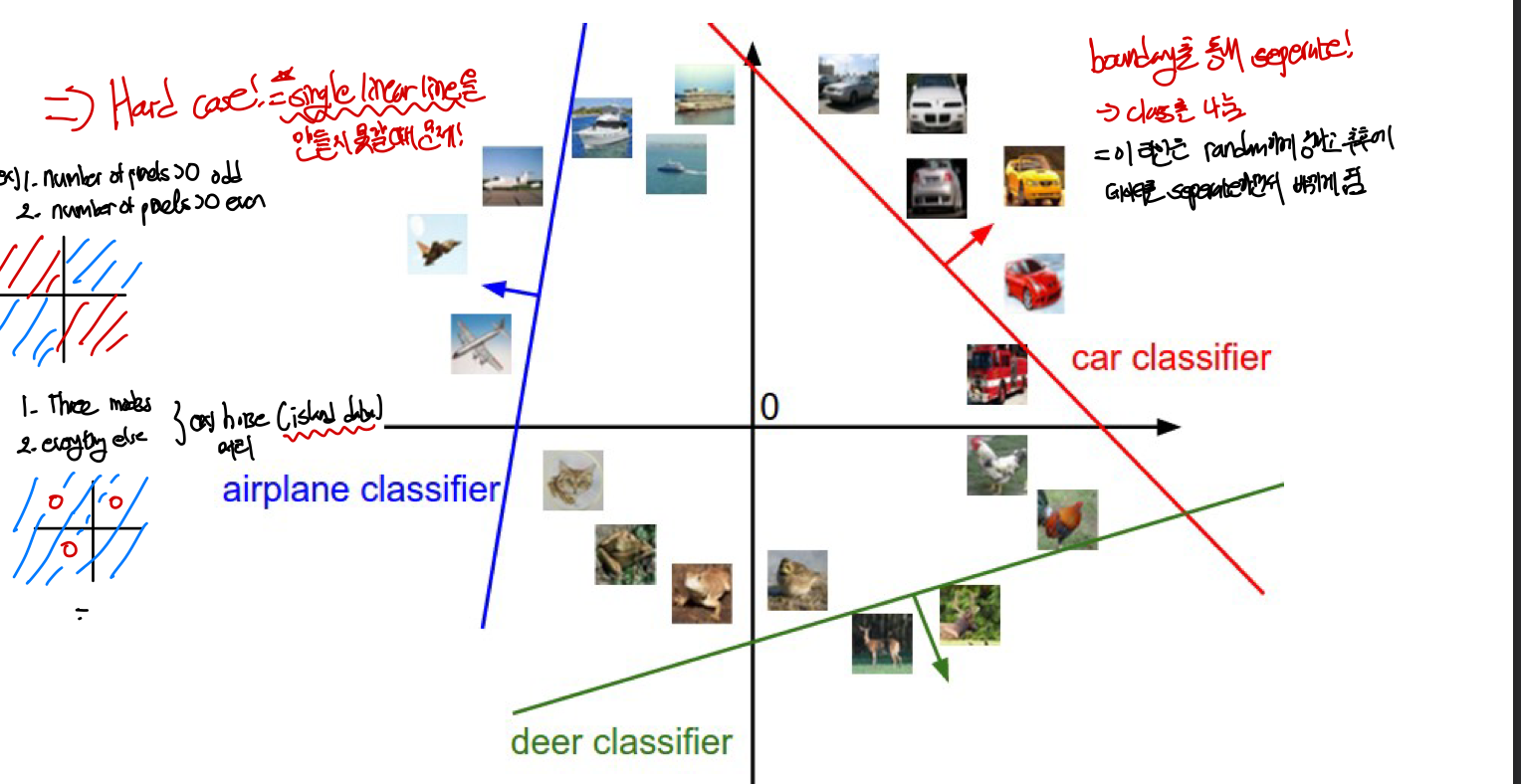
각 class score는 이 고치원 공간 상에서 선형함수값으로 표현이 되어 class에 대한 score을 이미지의 모든 픽셀에 대한 가중치의 합으로 정의힌다. 그래프 상에서의 선(boundary)이 곧 각 class의 class score가 0이 되는 지점을 뜻하고 W는 학습이 끝난 뒤에는 정해져있는 값이기 때문에 2차원이라고 생각해봤을때 직선(boundary)하나로 class score가 0인 곳을 알 수 있으며 이보다 크면 positive score 값(이 image가 이 class에 속한다!)을 얻는 것을 알 수 있다. 주로 이러한 boundary를 통해 separate하는데 맨처음에 random하게 정하고 나중에 바뀌게 된다. 즉, 이미지를 고차원상에서의 점으로 표현할 떄는 boundary(선형함수로 표현된 score function) 정하는 것이 곧 W를 정하는 것과 같다고 볼 수 있다.
- W=기울기: 각 행은 각각의 class를 구별하는 classifier이며 하나의 행을 바꾸면 픽셀 공간에서 해당하는 선이 다른 방향으로 회전할 것이다
- b=y절편: classifier가 평행이동하게 해주어 특히 xi가 0일때 모든 parameter값이 0이되어 원점을 지나는 것을 막게해주어 곧 각 class마다 의존적이지 않게 만들어주어 분류에 더 용이하게 만든다.
문제점: 만약 하나의 선형적인 선으로 구별을 하지 못할 때 문제가 되게 됨(hard case!!)
- 각 영역이 이어져있지 않을떄(1,3분면 vs 2,4분면)
- island data: 데이터가 혼자 떨어져있을 때 horse head가 2개가 나온 것처럼 문제가 생길 수 있는데 이는 Linear Classifier가 하나의 template만을 만들어내기 떄문에 개별적인 특징을 모두 담으려고 하는 과정에서 일어나는 경우이다.
B. Interpretation a linear classifier as template matching
template matching에 관점에서 이해해보자!
W의 각각의 행(row)는 곧 각 class별 template이 된다.(위에서 말했듯이 W의 차원은 class의 개수, 각 행은 특정 class에서의 값들을 의미!) 이미지의 각 들간의 내적(inner product)으로 계산이 되며 각 이미지 input에 댛ㅐ 통해 하나하나 비교하여 계산을 하여 score을 기준으로 가장 잘 알맞는 class를 구하게 된다. 즉, linear classifier는 template matching을 하고 있고, 각 template는 학습을 통해 배워진다
수천장의 training image를 가지지만 각 class마다 하나의 template만을 학습하는 것이 linear classifier에 문제라고 볼 수 있다. 이는 나중에 신경망으로 해결이 가능한데 여러 layer들을 이용한 학습을 통해 다양한 모습들을 학습 가능하이 가능하게 만든다. 예를 들어 머리가 2개인 말, training set에 빨간 색 truck이 많을 경우 template이 빨간색 truck인 경우가 생기는데 이는 후에 neural network 를 통해 해결이 가능함
결국에 Linear Classification은 단 하나의 이미지(탬플릿)으로만 새로운 사진과 얼마나 유사할지를 확인하게 되며 NN알고리즘과 다른 점은 L1, L2 distance를 사용하지 않고 내적을 사용을 사용한다는 것이고

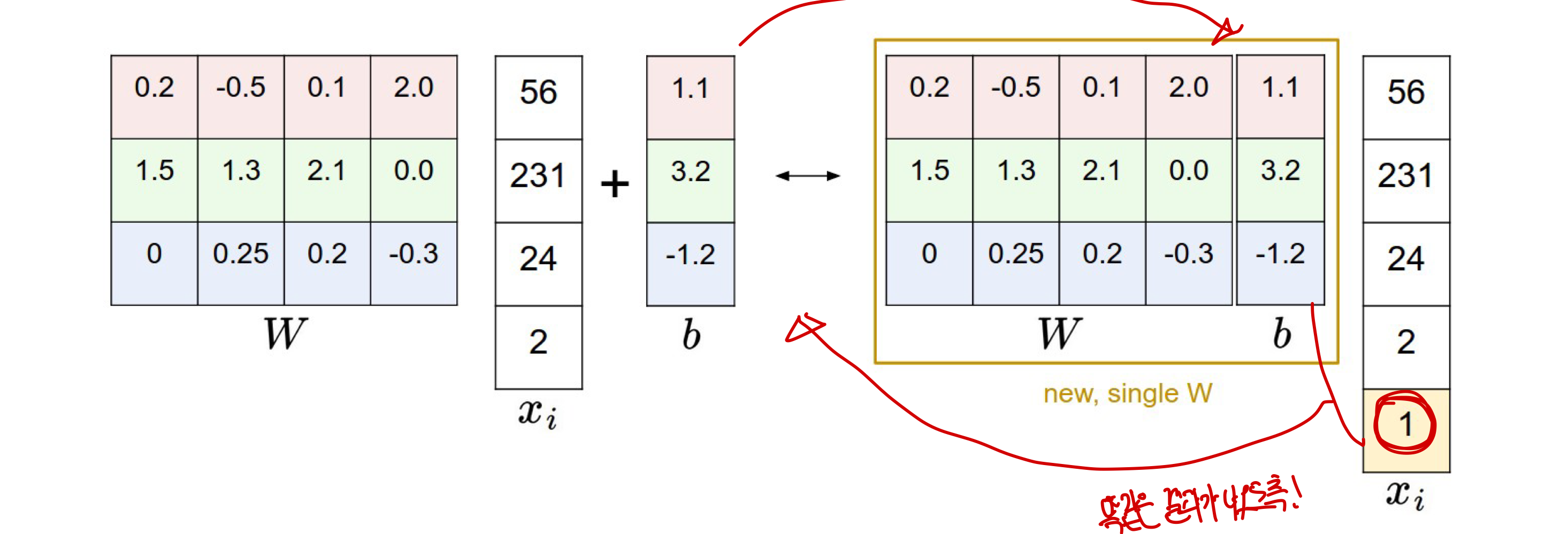
bias trick
bias인 b를 W에 추가하고 xi 열 백터 마지막에 1을 추가함으로써 더 간단하게 표현이 가능하다.