{kind=link}
현재까지는 input이 주어지면 이것이 어떤 class에 들어가는지 구별하는, 즉 input이 하나이고 이에 대한 output이 하나인 모델에 대해서만 알아보았다. 이번 강의에서는 input이 하나 혹은 여러개일 때 output이 하나 혹은 여러개인 경우 어떻게 학습이 진행되는지 알아보고자 한다. CS231n 10-2. Multilayer RNN
Process Sequence
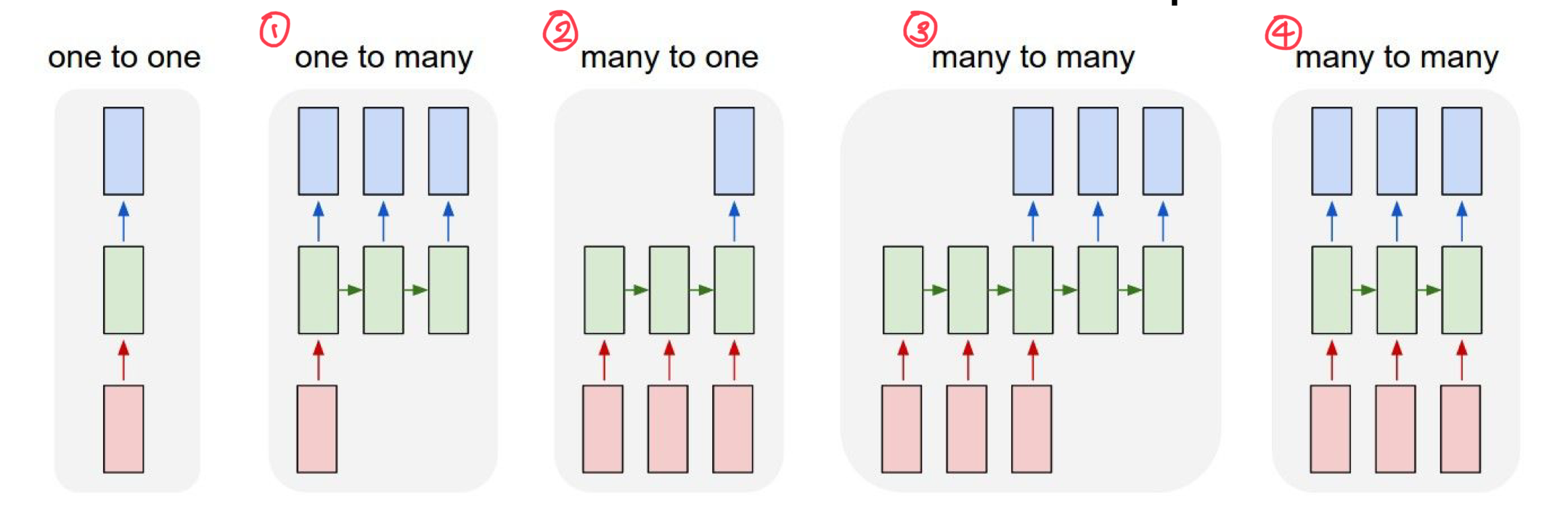
여기서 input은 모두 sequence하며 가변길이를 가지고 있는 것이 특징이며 다양한 종류의 경우에 대해서 간단하게 알아보면 다음과 같다
- one to many:
- ex) Image Captioning: image를 input으로 받아 어떤 사진인지 단어로 해석하여 output을 만들어냄
- output이 여러개 인 경우이다
- many to one
- ex) Sentiment Classification: 단어들의 연속를 input으로 받아 어떤 감정이 주가 되는지 하나의 output으로 만들어냄
- input(many)에는 text들의 집합이나 video가 들어가며 이것이 어떤 행동인지 알아내는데 주로 사용된다
- many to many
- ex) Machine Translation: 단어들의 연속을 입력으로 받아 단어들의 연속을 output으로 내보내는 모델
- 영어 문장을 한국어로 번역하는 모델같은 것이 대표적인 예이다.
- many to many(즉시 결과를 내보내야할 때!)
- ex) Video classification in frame level: 각 입력마다 바로 output을 만들어내는 것이 특징
- synced sequence로 연결되어 있으며 프레임마다 분류를 할 떄 주로 사용됨
Sequential Processing of Sequence Data
고정된 크기의 input과 output이라고 하더라도 ‘가변과정’ 인 경우에 RNN 사용 가능하다.
ex) 이미지와 같은 고정된 입력을 sequence하게 처리하여 이미지의 숫자가 몇인지 분류하는 문제!
- 돌아다니면서 이미지의 다른 부분을 확인(glimpse)하여 이미지를 분류하는 것이 특징
- 숫자들의 image input을 통해 새로운 이미지를 내보냄
- 순차적으로 전체 출력의 일부분씩 생성하는 것인데 output size가 고정되어 있어도 일부분씩 순차적 처리 가능

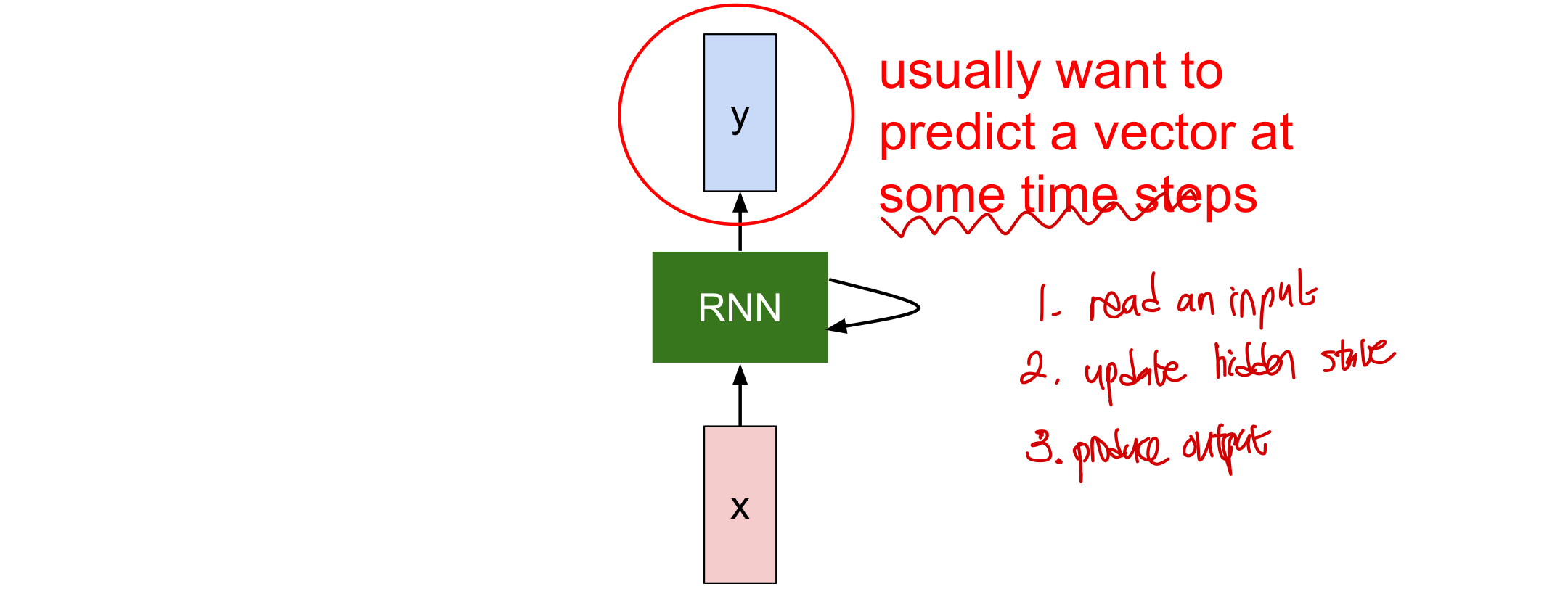
RNN이란?
가장 기본이 되는 동작 방식은 다음/과 같다.
- 입력 x를 읽는다
- hidden state를 update한다 ➡️ internal hidden state가 RNN이 새로운 input을 읽을 때마다 update가 되고 다시 RNN으로 들어가 또다른 input이 됨
- 결과값을 만들어낸다.
기본 RNN의 구성 요소
- : 특정 시간 단계에서 새로 들어오는 input vector
- : 이전의 state로 이 결과를 이용해 다음 hidden state를 update하는데 사용됨
- : parameter 를 가지는 함수로 과 를 입력으로 받아 hidden state를 update하는 역할을 하며 간 단계마다 같은 function과 parameter 를 사용해야함
- : 새로운 state로 과 함께 다음 state를 만들기 위한 의 input이 된다. 또한 FC layer을 추가하여 decision 혹은 output을 내보내게 됨!

기본 RNN의 계산과정
- parameter은 크게 3가지 사용되는데 1) : old state와 연산되는 parameter 2) 새로운 input와 연산되는 parameter 3) : function의 output을 특정 예측을 위해 연산되는 parameter
- fucntion은 -1과 1 사이에 값으로 만드는Tanh 를 사용하며 왜 문제점이 많은 tanh를 쓰는지는 나중에 알아본다고 한다. LSTM에서는 다른 방식을 사용한다고 한다 CS231n 6-1. Setting Up Architecture (Activation Functions)

Computational Graph
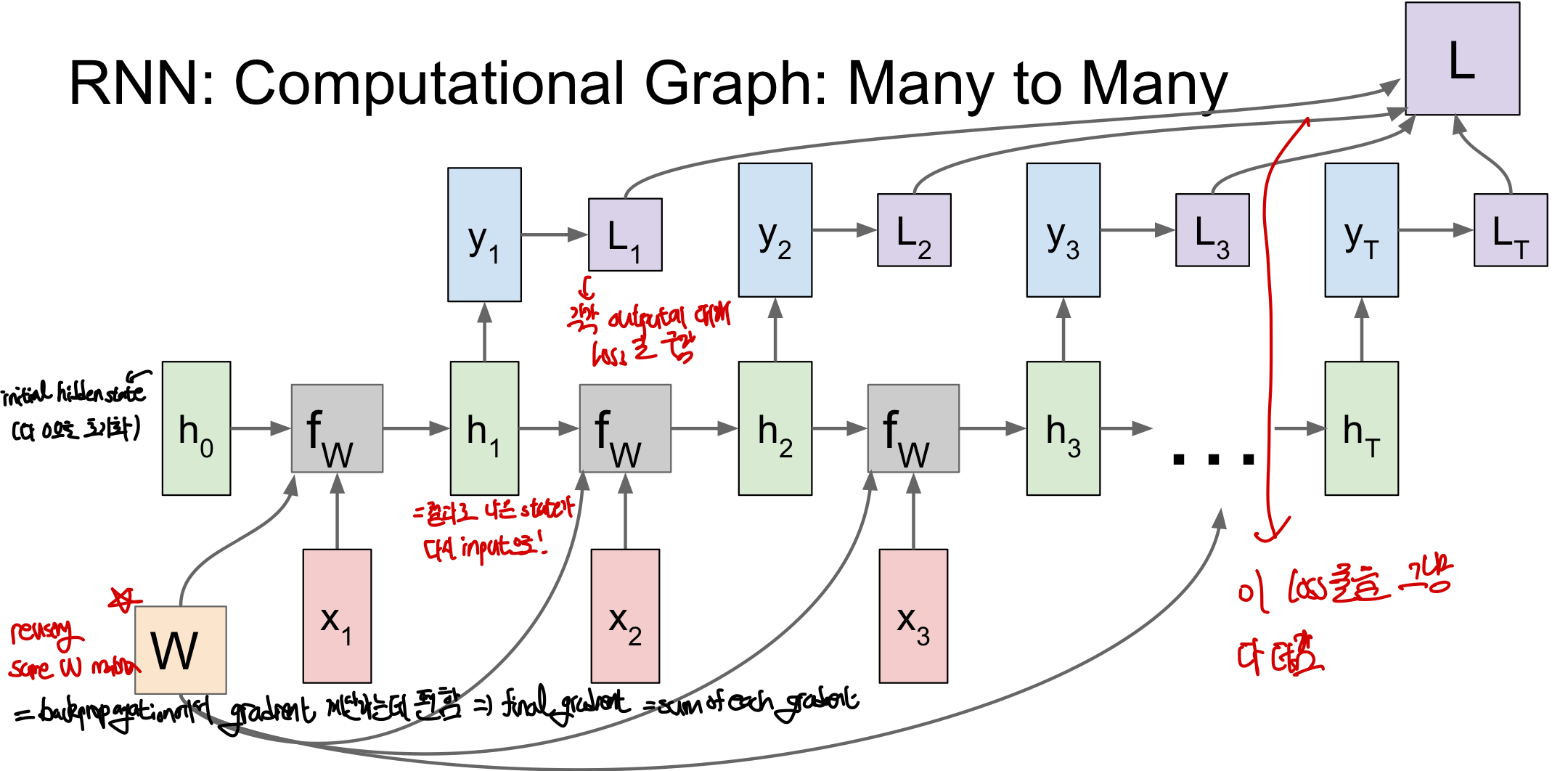
이해를 쉽게 하기 위해서 RNN에서 반복적으로 일어나는 일련의 동작들을 unrolling 즉, 펼쳐서 computational graph로 표현하면 다음과 같이 이해하기 쉽게나타낼 수 있따.
- Many to Many: (Machine Translation: 번역등의 일을 담당)
- 맨 처음의 hidden state를 0으로 초기화하여 function에 input으로 넣음
- function의 결과로 나온 state가 다시 input으로 들어가는 형태가 반복됨
- Weight parameter들을 각 function에 넣어 계산을 하고 이때 W는 같은 값으로 이루어짐
- 각 output y(class score)마다 loss를 구하고 이 loss를 모두 더한 후 최종 loss를 구해 backpropagation을 하게 된다. 이때 각 단계마다 gradient를 통해 가 얼마나 변해야하는지를 결정하는 것을 반복하여 결과적으로 이것을 합하여 update가 이루어진다
- Many to One: (Sentiment Classification)
- 마지막 hidden state가 현재까지의 모든 sequence의 결과를 요약하게 됨

- 마지막 hidden state가 현재까지의 모든 sequence의 결과를 요약하게 됨
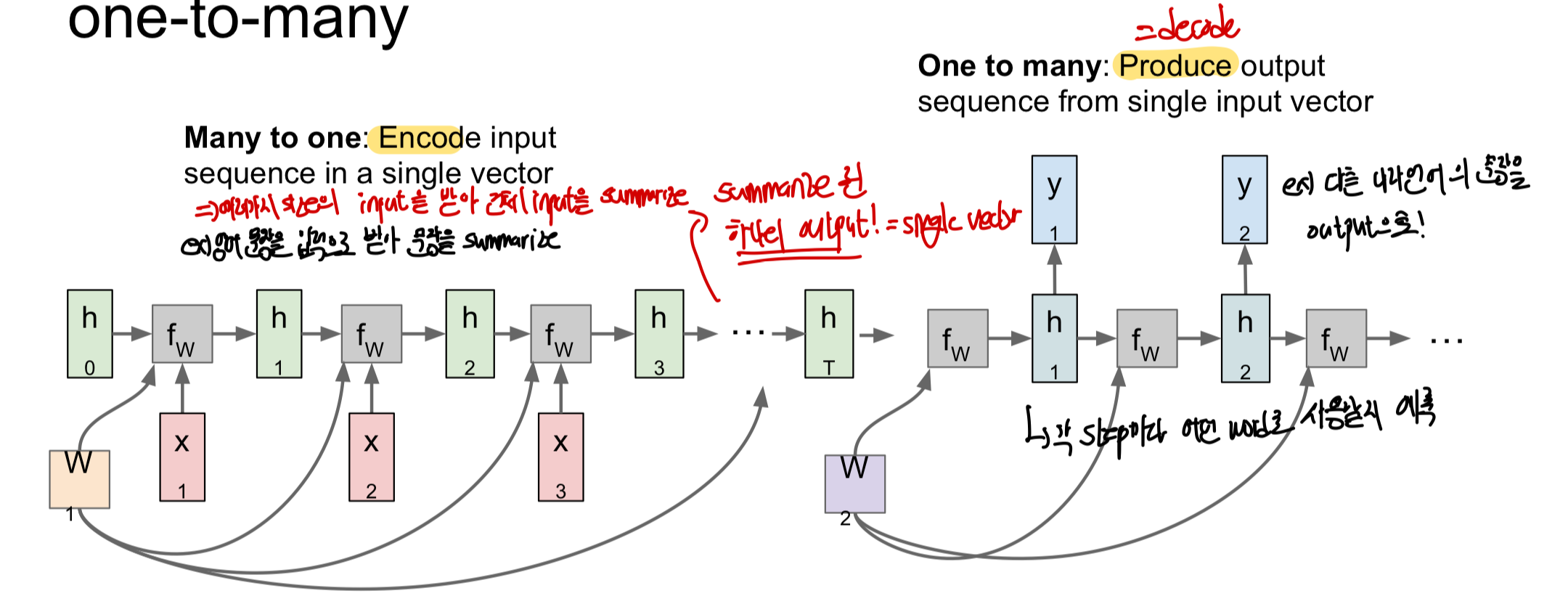
- One to Many: (Image Captioning)
- 하나의 고정된 입력은 initial hidden state를 초기화하는 용도로 사용
- 위에서 언급한 고정된 입력에 가변적인 output을 갖는 network!

- Many to One + One to Many: (번역: 영어 문장을 한국어 문장으로 바꾸는 것)
- Many to One: 여러 가변 입력을 요약하여 하나의 feature vector로 만듦 (encoding)
- One to Many: 앞서 받은 vector을 입력으로 받아 가변 출력을 output(decode!)
- Many to Many 를 이와 같은 형식으로 합친 이유는 CNN + RNN을 합칠 때 이와 비슷하게 CNN은 하나의 output을 내보내고 이를 input으로 받은 RNN은 여러가지 답을 하기 때문인 것이 일반적이기 때문이다.
Character-level Language Model (Sampling)
위와 같은 과정을 문장에 대해서만 할 수 있는 것이 아니라 각 문자가 어떻게 나오게 될지에도 활용이 가능하다. 일련의 문자들이 입력으로 들어왔을 때 다음에 어떤 문자가 오게 될지 학습하는 과정을 알아보고자 한다.
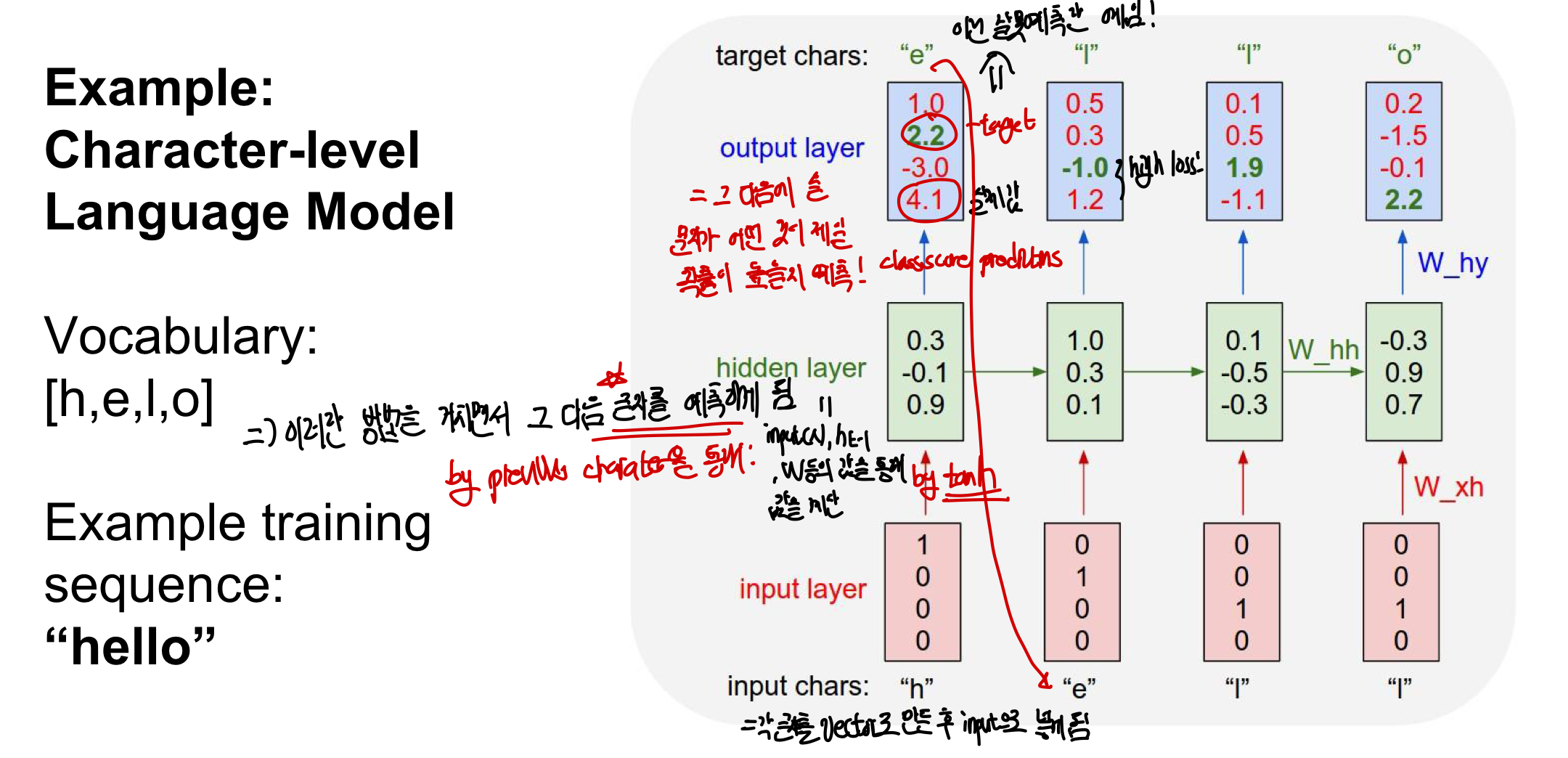
Training 어떻게 모델l이 학습을 하여 natural language를 생산해내는지 보자!
- 각 character(문자)를 vector로 만든 후에 tanh함수를 통과하여 hidden state값이 update됨
- Full Connected를 통해 class score을 구해서 예측을 한 뒤 output weight 와의 연산을 통해 loss를 구함
- 잘못된 예측을 한 경우 loss만큼 변화시켜 weight의 값을 update함
예를 들어 첫번째 문자가 h가 들어왔을 때 이를 vector로 으로 표현한 뒤 hidden state 값을 update 한 뒤에 output에서 나온 결과를 보면 그 다음에 와야할 문자는 e이지만 모델은 o라고 예측하고 있다. 이럴 경우 loss를 발생시켜 weight를 변화시킨다. 이러한 과정을 반복해서 학습시켜 model들이 이전의 문장들의 문맥을 참고해서 다음 문자가 무엇일지 예측 가능하게 된다
Test-time 여기서 중요한 것은 class score가 높은 문자가 꼭 다음에 오는 문자가 되지는 않는다는 것이다!Softmax 함수를 이용하여 확률적으로 값을 만들고 여기서 다음에 올 문자를 확률에 따라 sample하여 sample된 문자가 다음 input이 된다 CS231n 2-2. Linear Classification (Loss function)
- 여전히 hidden state에는 이전의 값이 영향을 미치며 값에 따라 state가 update가 된다
- 그럴 듯한 다양한 문장들을 출력할 수 있다!
왜 가장 높은 확률값의 문자를 뽑지 않고 Sampe을 할까?
- 이 probability distribution에서 가장 높은 값을 갖는 문자가 꼭 찾고자 하는 문자일 보장이 없음 ➡️ 예를 들어 맨 처음의 h 다음에 e가 운좋게 확률이 낮음에도 맞게 뽑힐 수 있음
- 모델의 다양성를 보장해줌 ➡️ 어떨때는 고정된 prefix처럼 확률이 높은 값들이 뽑히고 어떨 때는 새로운 값이 뽑혀 다양성을 유지시킴
왜 문자를 test의 다음 입력을 하나의 문자만을 뽑을까?
다음 입력이 되는 vector을 softmax의 결과가 되는 dense vector가 아닌 하나의 문자를 뽑아 하나의 위치에만 1이 들어있는 sparse vector로 만드는데 이는, softmax의 결과값을 다음 step에 입력으로 넣을 경우 연산적으로 매우 복잡해지기 때문이다. 특히 나중에 문자가 아닌 단어에 비슷한 모델을 구현할 경우 softmax 결과값 vector에 수천,수만개에 값들이 존재하게 되는데 이것을 모두 처리하는 것이 매우 비효율적이다.

Backpropagation
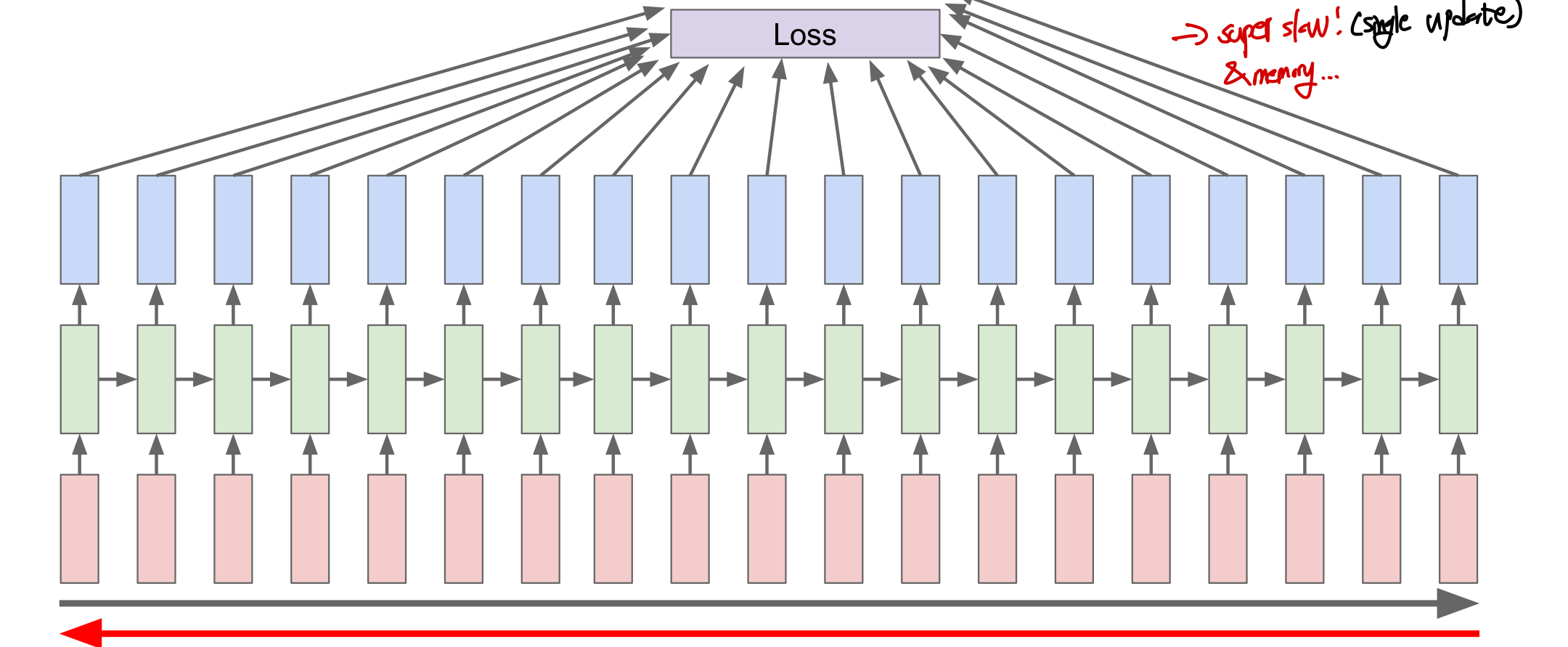
가장 원시적인 방법: 기존에 방식대로 가장 간단하게 생각할 경우 매우 느릴 뿐 아니라 메모리 문제도 생기게 된다. 모든 sequence를 forward pass하여 loss를 얻고 gradient를 계산하기 위해 모든 sequence를 backward하여 update를 진행하는데, 이것을 위키피디아 같이 매우 큰 단어 조합에 적용하게 될 경우 단 한번의 update를 하는데 매우 오랜시간이 걸려 수렴을 하지 못하게 된다
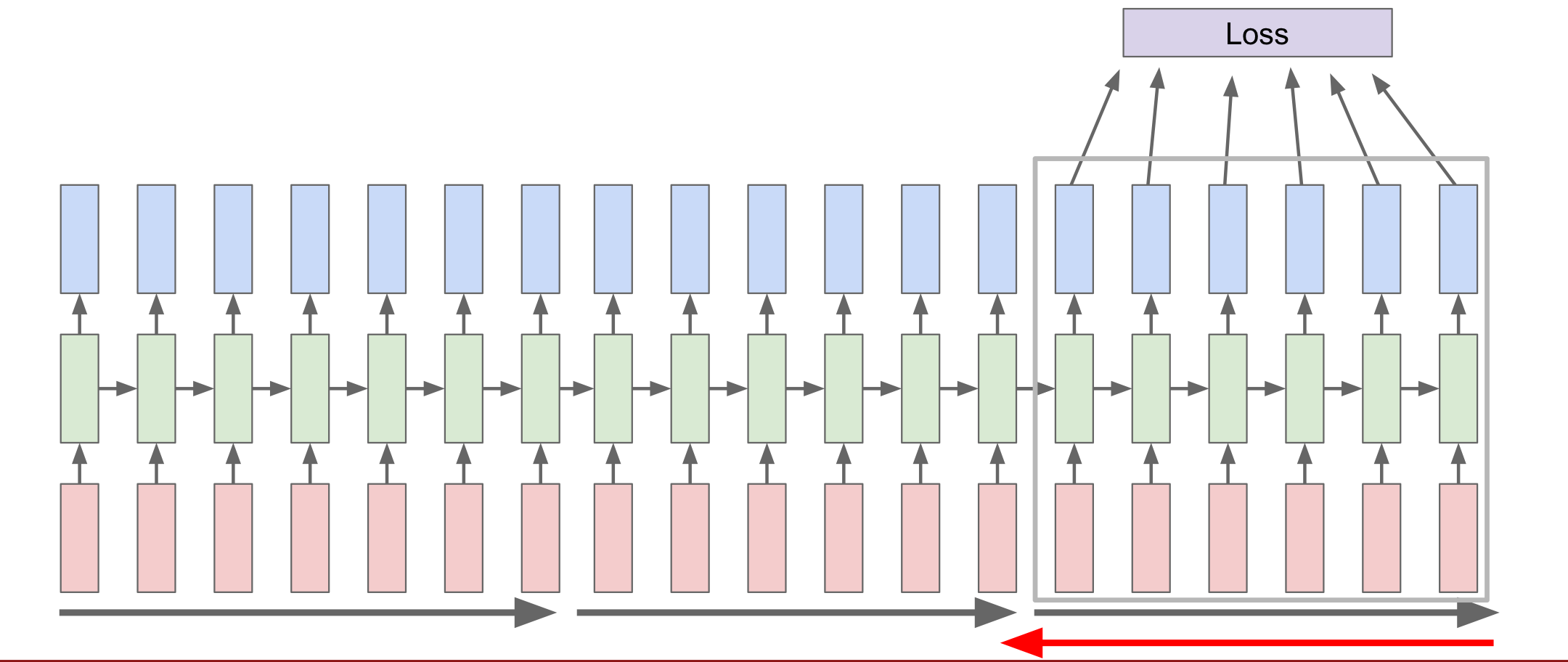
해결 방안: Truncated Backpropagation(approximation) ➡️ sgd가 모든 입력 이미지에 대해서 gradient를 구해 update하는 것이 비효율적이기 때문에 특정 batch를 뽑아 update를 했던 것과 비슷하게 특정 batch마다 backpropagation을 진행하는 방법이다.SGD
- forward하다가 특정 step을 지나게 되면 지나간 부분만큼 backward하여 gradient를 계산하게 됨
- 이때 forward pass는 지속적으로 앞으로 나아간다.
즉, gradient step은 현재 batch에서만, 다음 batch를 계산하기 위한 forward pass는 이전 hidden state를 가져와 계산을 하는 방식이다.
이런 방식들을 이용해 특정 작가의 글을 학습시켜 이와 비슷하게 글을 쓰게 만들거나 latex의 사용방법을 학습시켜 수학적으로 의미있어보이게 글을 쓸 수 있거나 c언어를 학습시켜 c언어 코드와 유사하게 만들 수 있다고 한다.
활용방안
Searching for interpretable cell
모델이 도대체 어떤 방식으로 학습을 하고 있을까? hidden layer에는 vector가 있고 이 vector가 계속해서 업데이트 되기 때문에 이 vector을 추출하여 해석하면 hidden state가 무엇을 바라보고 있는지 확인할 수 있을 것이다. 즉, hidden vector의 vector을 뽑아 다른 hidden state들이 무엇을 찾고 있고 의미하는지 확인을 해본다!
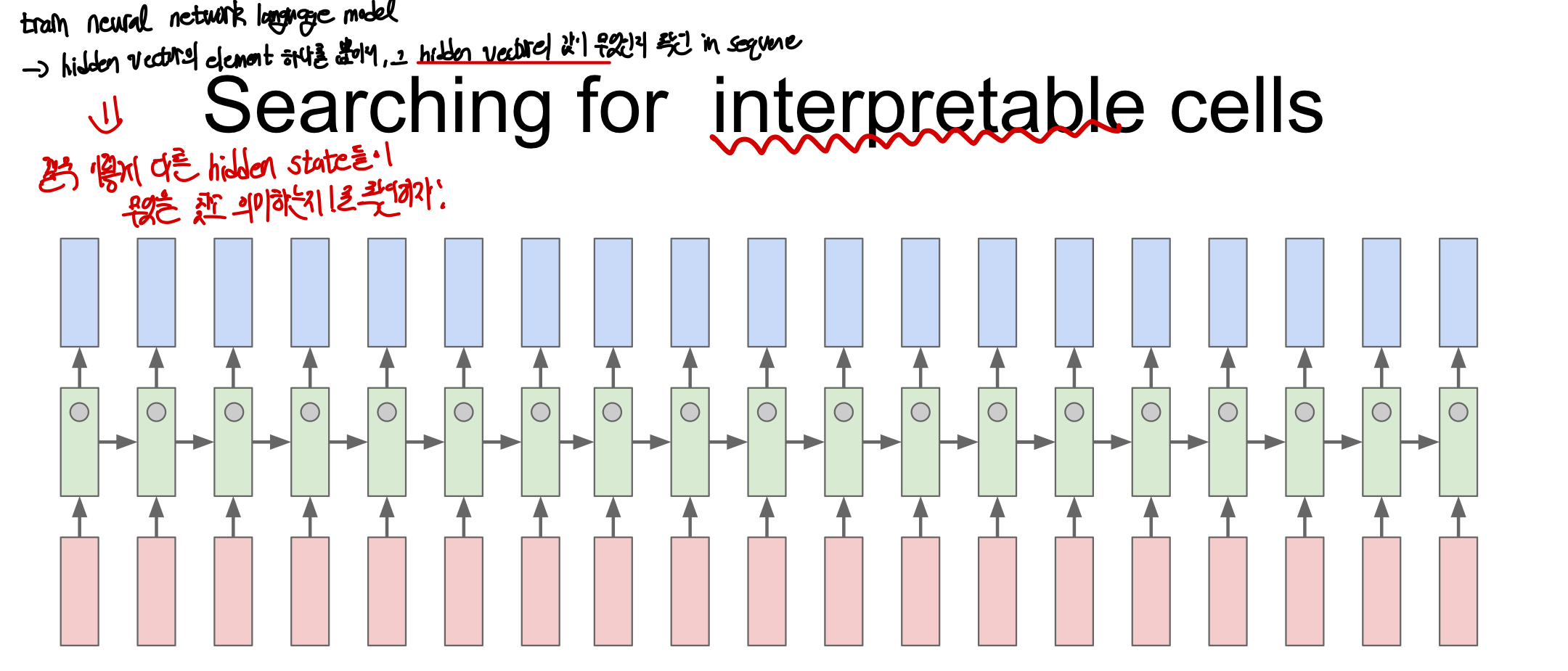
- 밑에 사진 중 아래 그림과 같이, 각 vector가 보고 있는 부분이 띄엄띄엄 떨어져 있으며 이는 hidden state가 아무 의미 없는 패턴을 갖고 대부분 해석하기 어렵다는 것을 알 수 있다 (vector 하나를 뽑아, 이 sequence를 forward시켰을 때)
- 학습을 하던중 어떤 vector가 아래 그림 중 위와 같이, 따옴표를 찾는 기능을 갖게 될 수 있다. 이 같은 경우는 모델이 다음 문자를 예측하도록 학습시켰지만 모델은 더 유용한 것을 학습하게 된 경우라고 볼 수 있다.
- 이와 같이 줄이 바뀌었을 때, c언어의 함수, 들여쓰기 등을 학습하는 특정 vector가 학습을 통해 생기게 된다는 것을 알 수있다.
즉, input data의 유용한 구조를 학습하게 되며 이는 곧 interpretable cell을 찾게 된다는 것을 알 수 있다 .같은 색깔은 sequence를 읽는 동안 앞에서 뽑은 hidden vector값을 의미하며 처음에는 색깔이 완전 달라 제대로 학습한 hidden vector이 없다는 것을 알 수 있지만 후에 2처럼 따운표를 찾는 유용한 vector을 찾아 학습이 가능한 것을 알 수 있다

Image Captioning
input이 image일 때 output을 natural language(가변길이)를 내놓는 기법!
- RNN에서는 output 단어가 다시 input으로 들어가는 것을 반복하면서 문장을 만듦
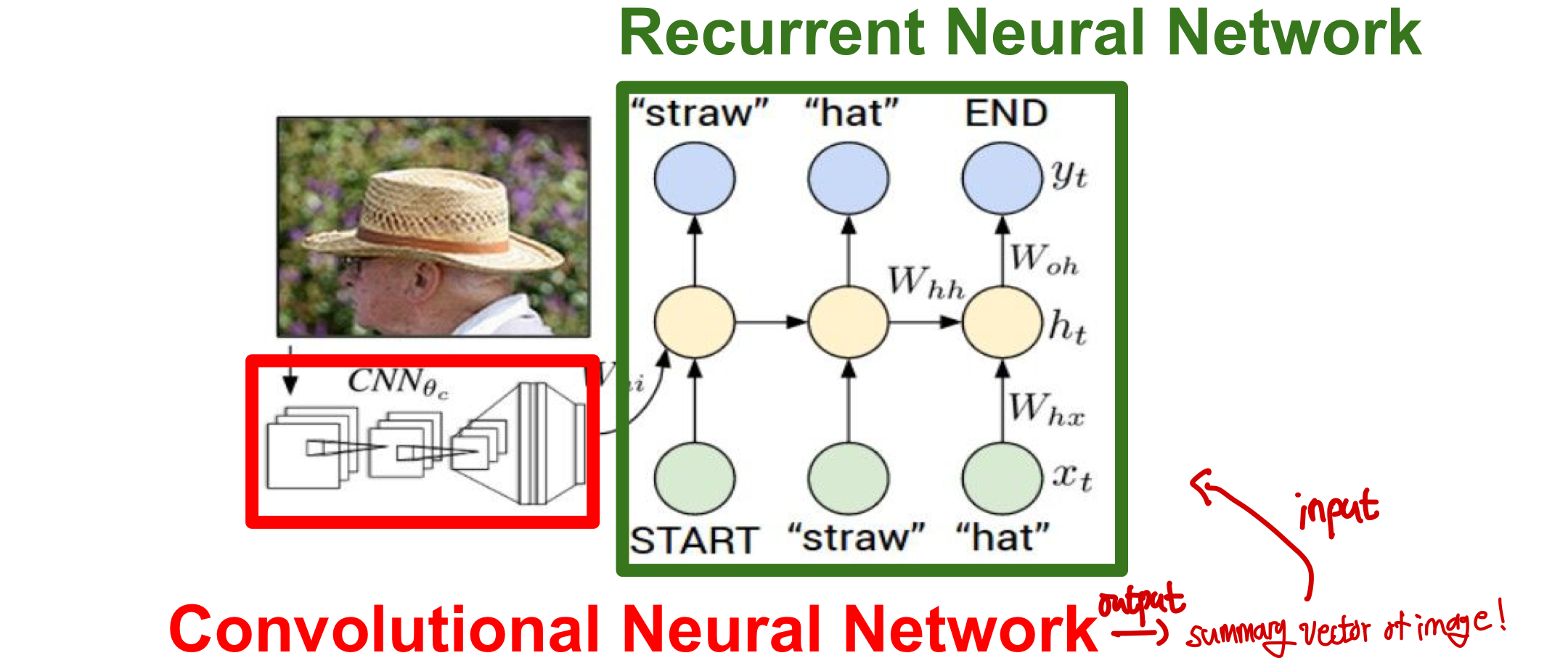 Image Captioning의 동작 방식(CNN+RNN)
Image Captioning의 동작 방식(CNN+RNN)
- 기존 CNN에 image를 입력으로 넣어 feature을 추출한다. 이때 softmax layer은 없을 없애고 4096차원 vector을 CNN에 output이자 RNN에 input으로 들어간다.
- 이 모델은 점수를 매겨 어떤 class에 들어가는지 예측하는 것이 목표가 아님
- RNN의 입력으로 image의 특성을 요약한 vector를 보내는 것이 목표!
- RNN 모델에 첫번째 x 입력으로 start token이 들어감
- image를 보고 문장을 만들어달라는 요구 내용이 들어가게 됨
- 기존의 tanh function의 input으로 CNN에서 사용한 백터를 이용해 image information을 추가! ➡️❓아마 첫번째 tanh에만 이렇게 들어가는 것 같기도..?
- x input, 이전 state의 값, image information이 state function의 입력으로 들어감
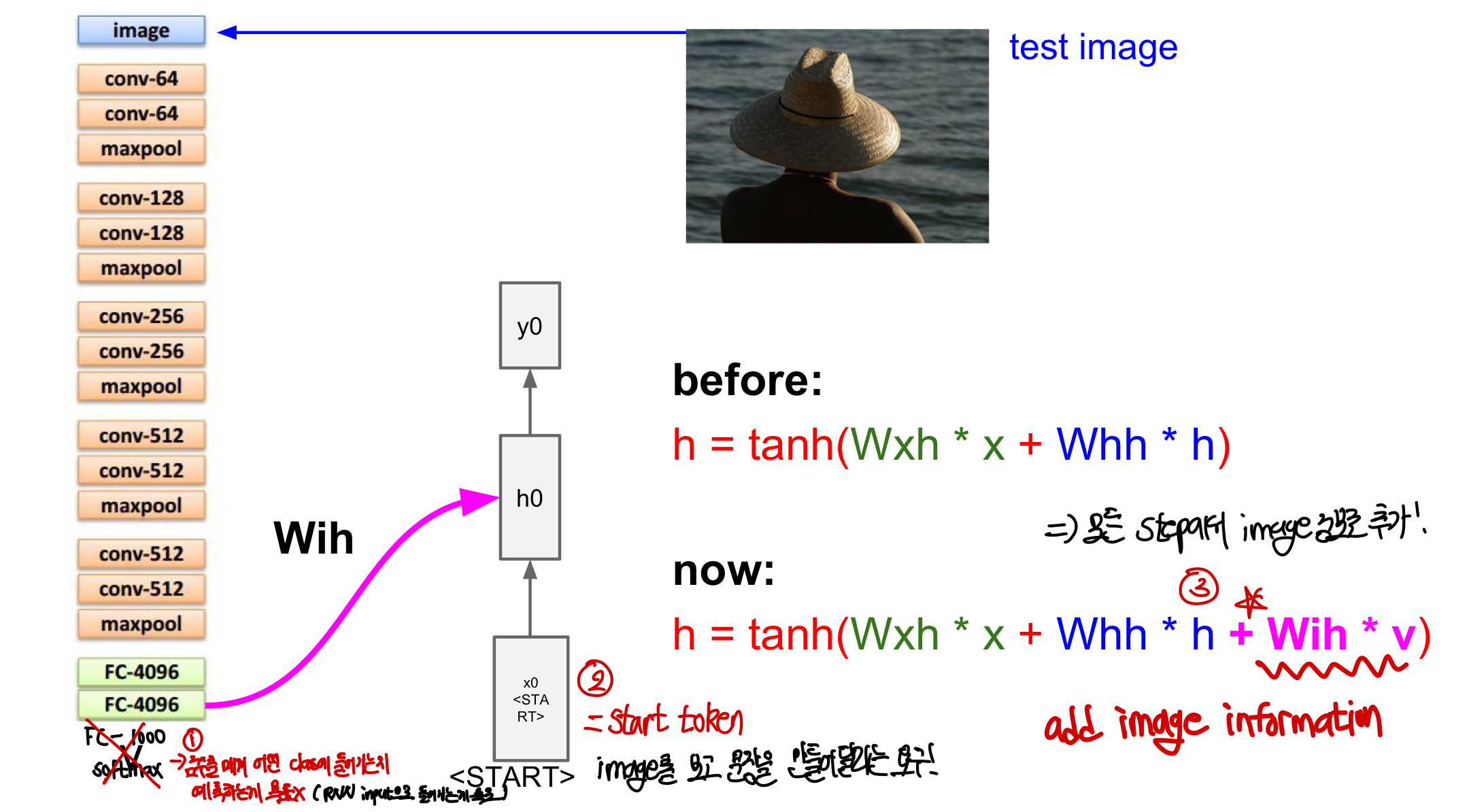
- x input, 이전 state의 값, image information이 state function의 입력으로 들어감
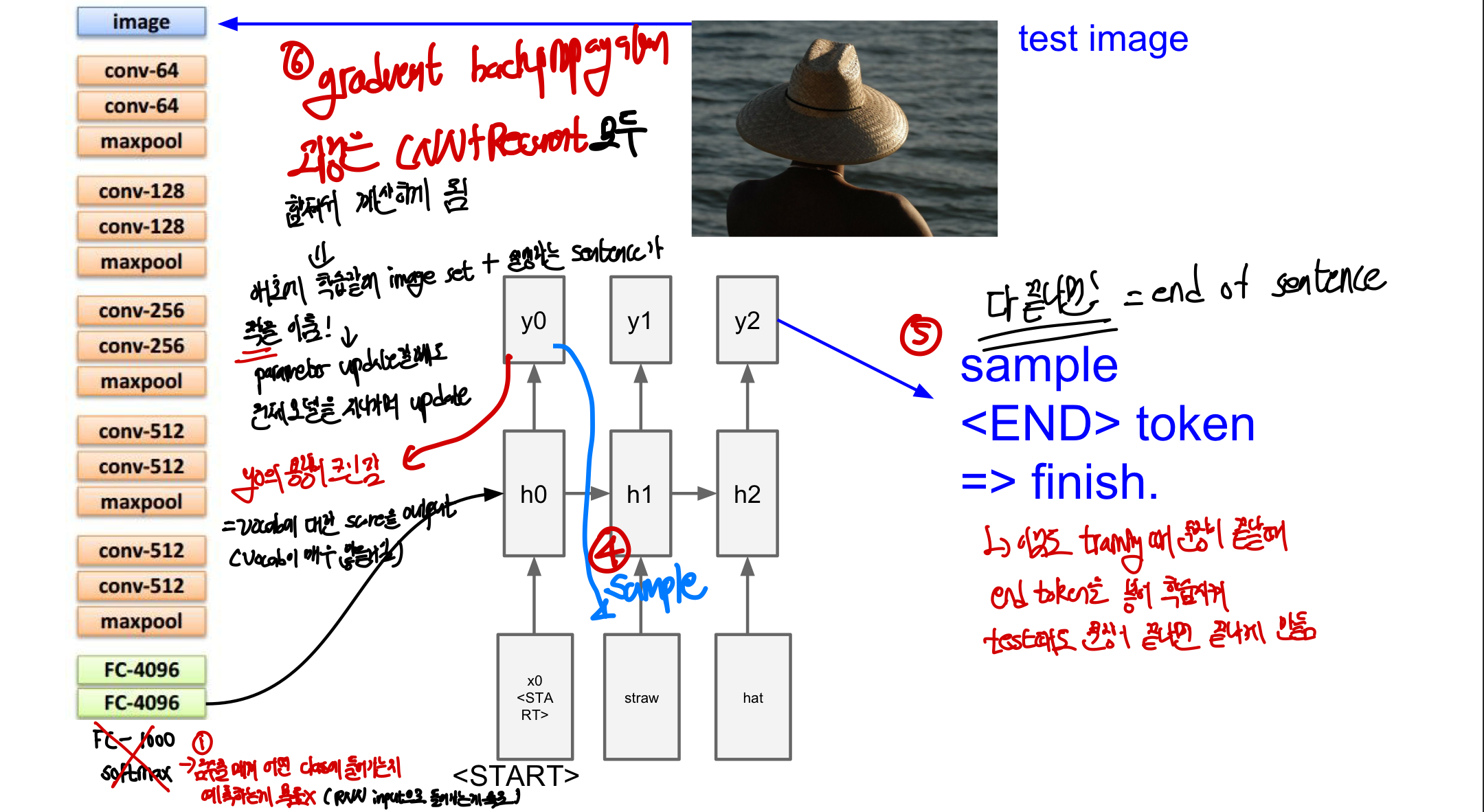
- softmax등의 함수를 이용해서 확률 분포를 만들고 단어 사전에서 하나를 sample
- 단어에 대한 score을 모두 구해야하기 때문에 많은 용량이 필요로 함
- sample된 단어는 그 다음의 x input으로 들어가게 됨
- End token을 sample하게 될 경우 종료된다.
- 이 token도 training때 같이 학습되어 문장이 끝난다고 판단했을 때 network의 작동을 끝나게 해준다
- gradient backpropagtion 과정은 CNN+RNN과정 모두 합쳐서 계산되어 진행
- 애초에 학습할 때 image set과 sentence가 짝을 이루며 pararmeter update도 전체모델을 지나가며 이루어진다
실제로 마이크로소프트의 COCO와 같이 image captioning 작업을 잘하는 모델이 존재하고, 실제로 놀라운 성능을 보이기는 하지만 다음과 같은 문제점이 존재한다.
- image captioning도 일종의 지도학습이므로 이 모델을 학습시키기 위해서는 이미지를 가지고 있어야 함
- 학습에 사용된 이미지가 아닌 새로운 data에 대해서 잘못된 문장을 만들어냄(모델이 새로운 단어를 찾을 수 없음)
- 질감이 비슷하거나 가장 사진의 특징적인 부분을 찾아내지 못하기도 하는등 복잡해 보이는 caption을 만들었지만 잘못예측하는 경우도 있다!
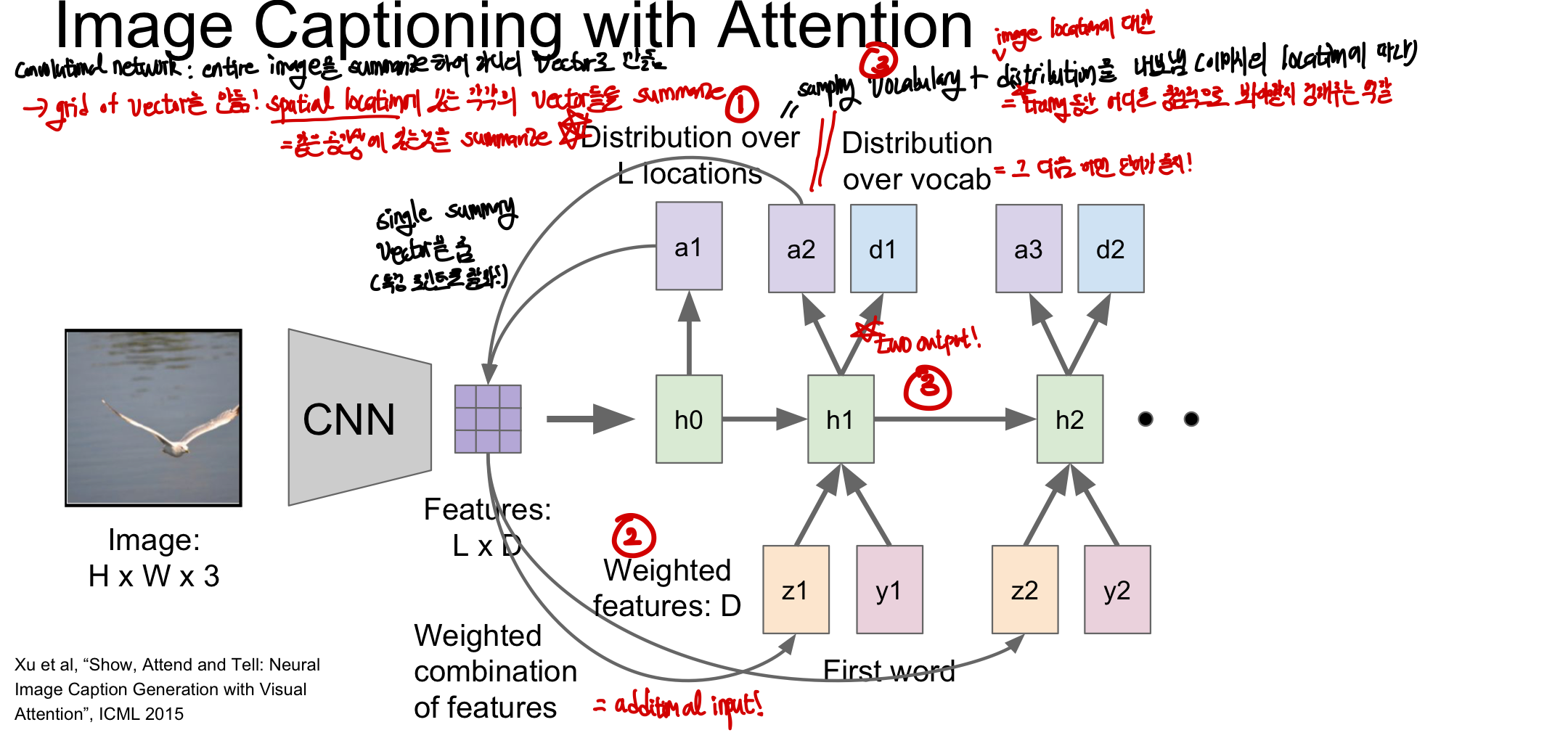
Image Captioning with Attention
Image Captioning의 발전될 모델로 학습을 할 때에 모델이 어느 위치를 봐야하는지를 이용해 학습하는 기법이다. 기존 CNN은 image 전체를 요약하여 하나의 vector로 표현했다면 여기서는 spatial location에 있는 각각의 vector들을 요약했다고 보면 된다. 즉, fc layer까지 진행한 것이 아니라 convolutional layer의 결과를 이용하여 이미지의 각 부분마다 고유한 feature을 학습하도록 만든 것이다
Attention 동작방식
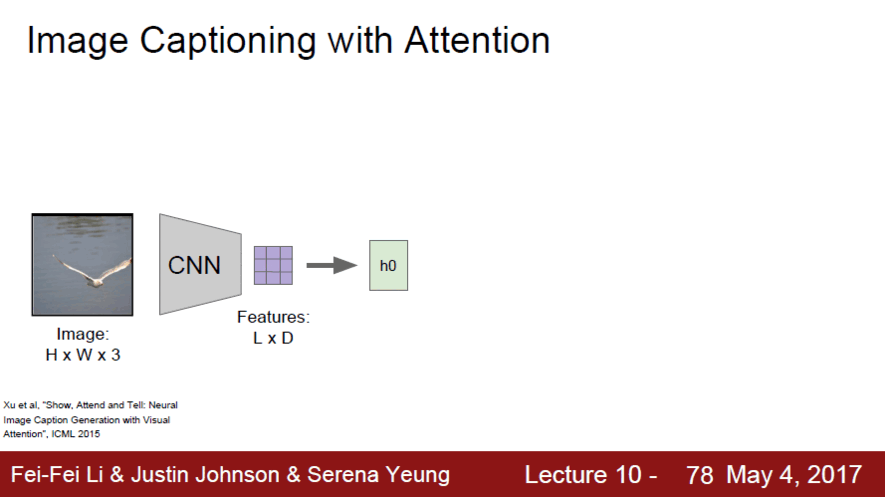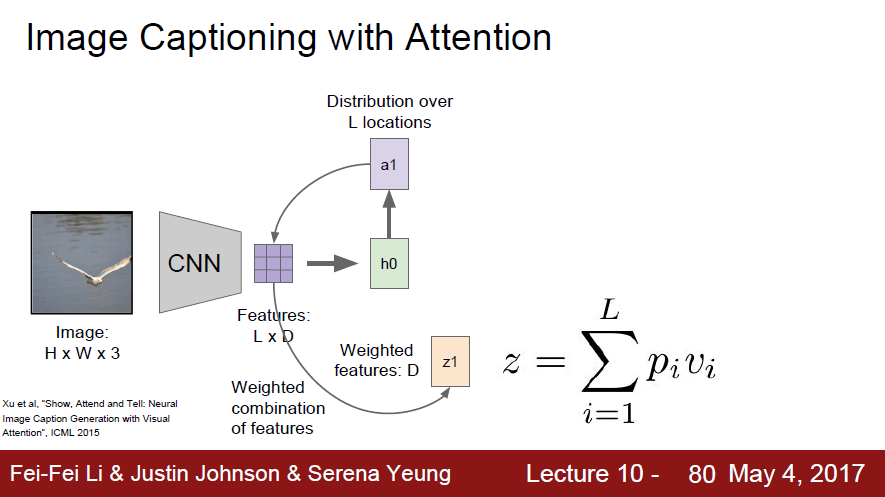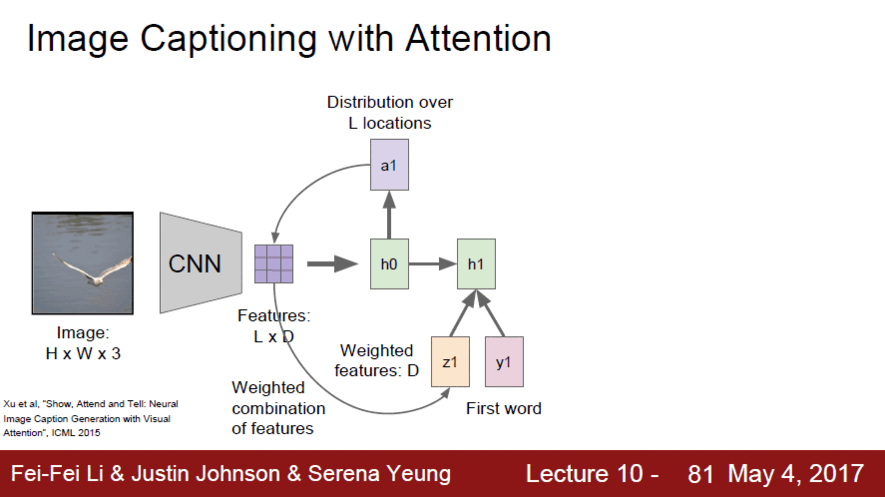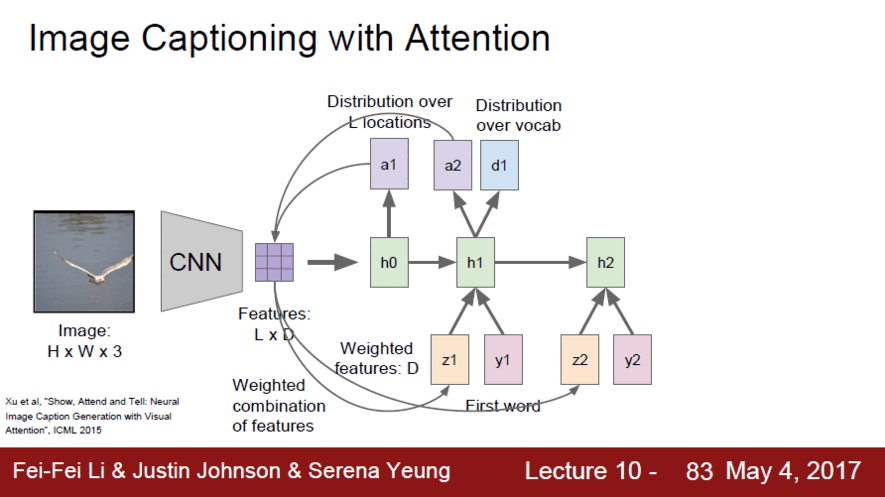
- CNN으로 요약된 vector들을 첫번째 hidden layer에 넣은 후 a1에서 기존 영역 중 어느 부분을 볼지 정함
- 하나의 요약된 vector을 주고 요약된 vector에서 어떤 부분을 볼지 학습된 분포를 통해 위치를 알아냄
- 집중적으로 볼 부분을 새로운 input으로 들어감
- x input이 하나에서 2개로 바뀌어 word input과 함께 공간정보가 새로운 input이 됨
- hidden state 에서 2개의 output을 내놓게 됨
- sampling vocabulary: 기존의 Image Captioning과 똑같은 output으로 다음 단어가 무엇이 될지 정한다
- sampling location: image location에 대한 distribution을 통해 어디를 볼지 정한다.
- 이후 2번과 3번 과정이 계속 반복되어 연속적으로 단어를 내보냄과 동시에 이미지에서 어디를 중점적으로 볼지 계산하여 정확도를 높인다.
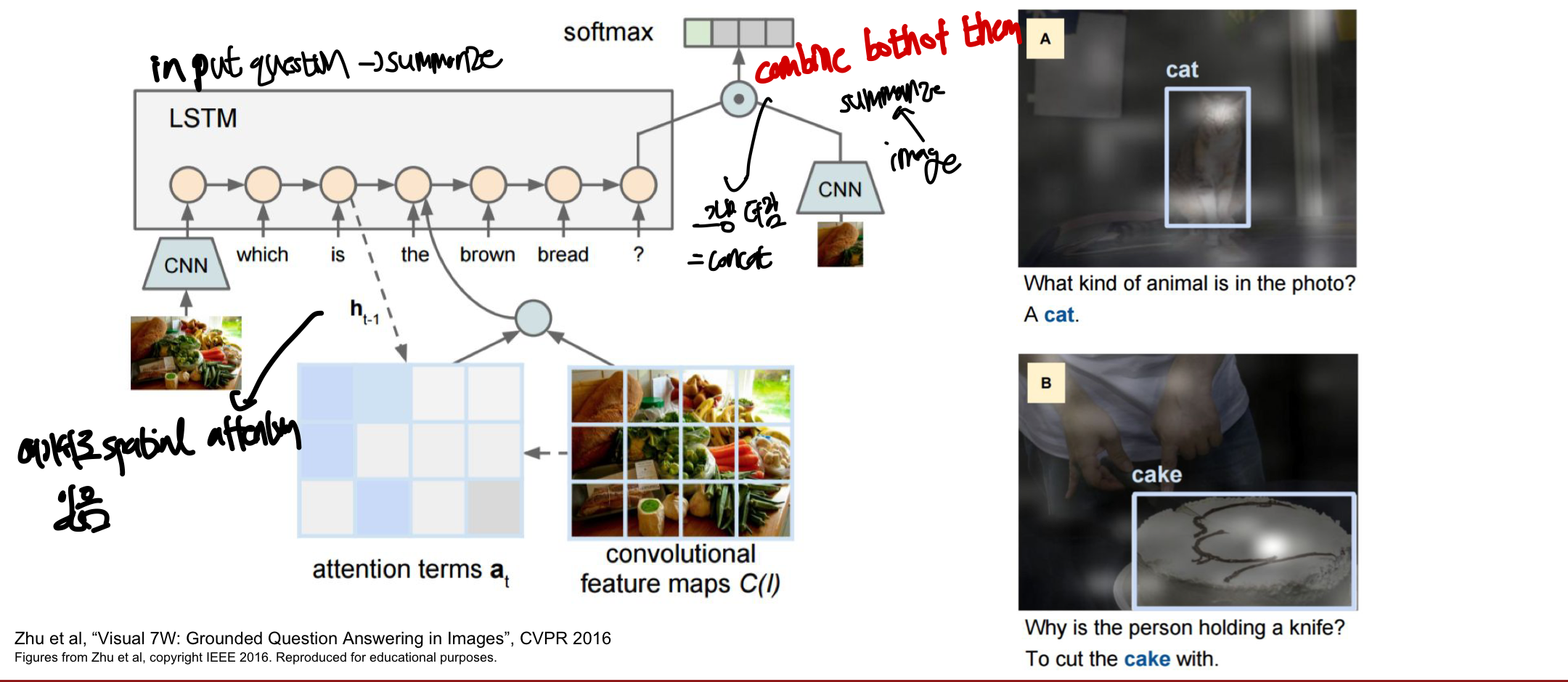
Visual Question Answering
attention을 이용한 또 다른 모델로 input을 image와 질문으로 주었을 때 모델이 4개의 보기중에 정답을 맞추는 문제로 전형적인 many to one 문제(many: 사진과 여러 단어들, one: 하나의 답)이다. 이때 RNN은 질문을 요약하여 vector로 만드는 역할을 CNN은 이미지를 요약하여 vector을 만드는 역할을 한다. 이후 이 두 vector을 단순히 더한 뒤 fc layer을 통해 학습을 시켜 질문에 대한 분포를 예측한다.